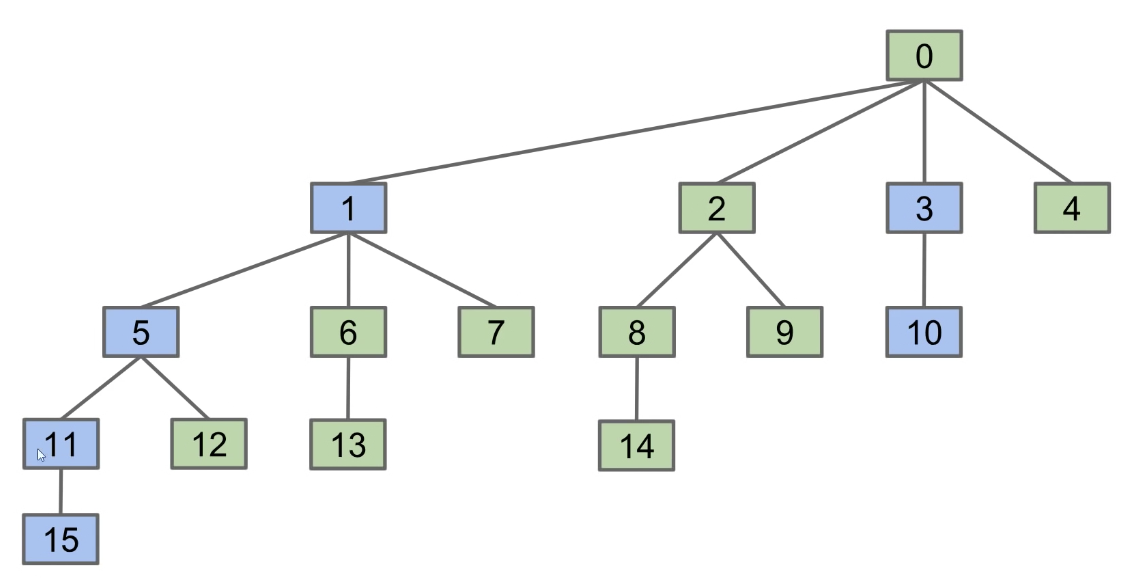
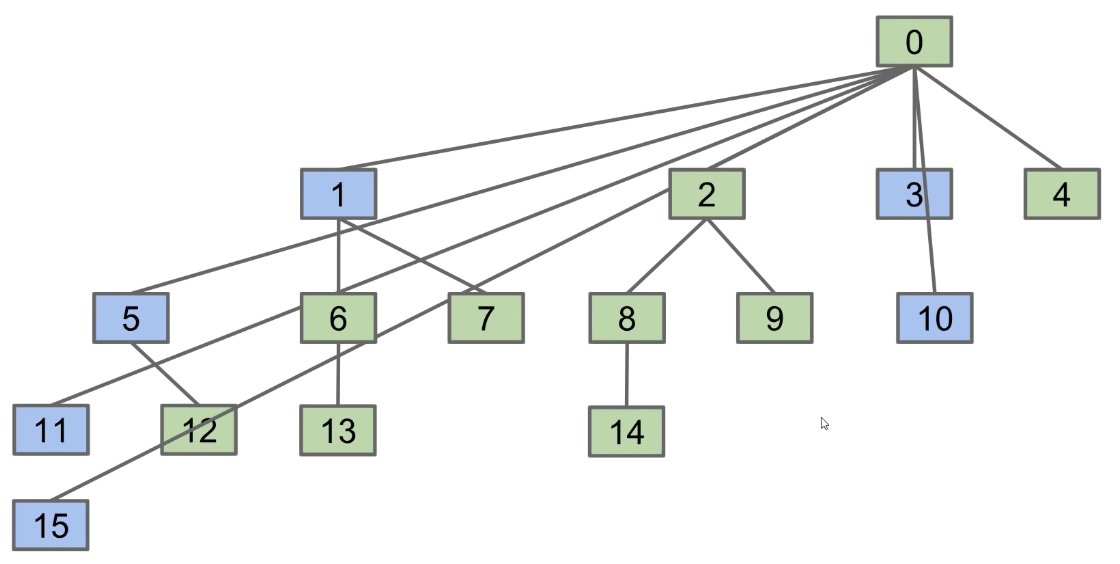
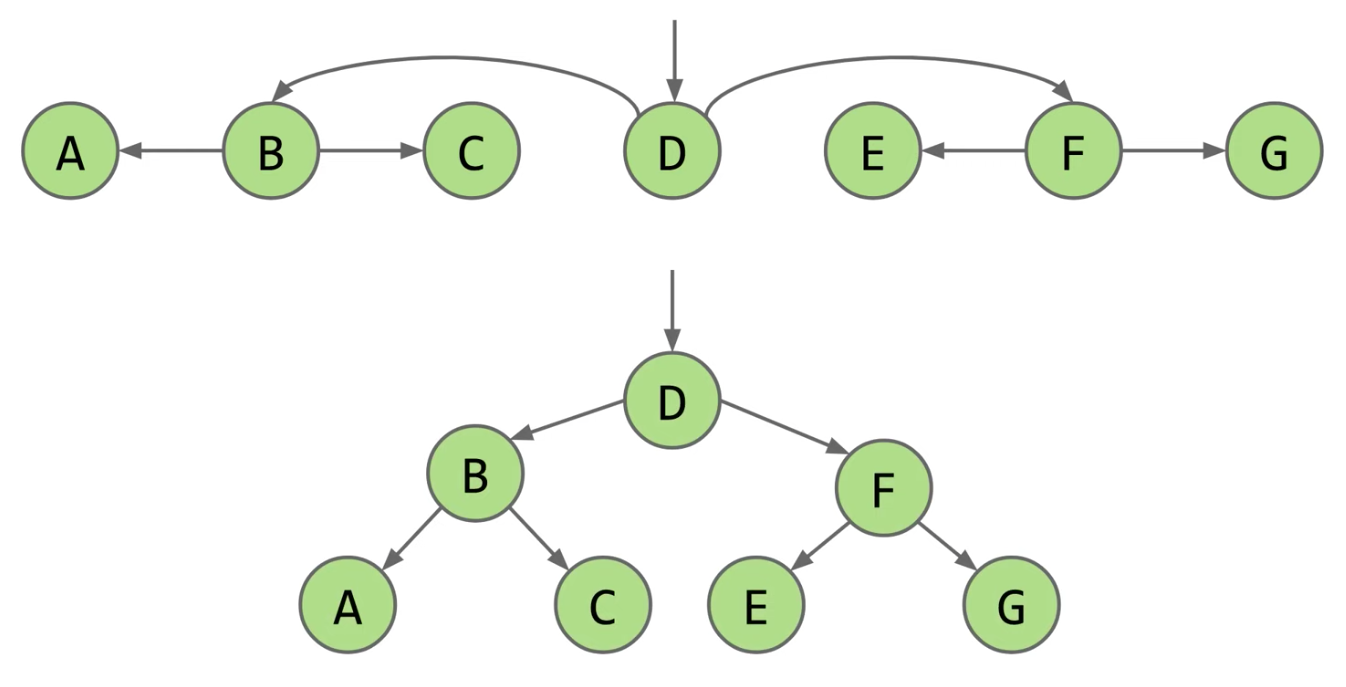
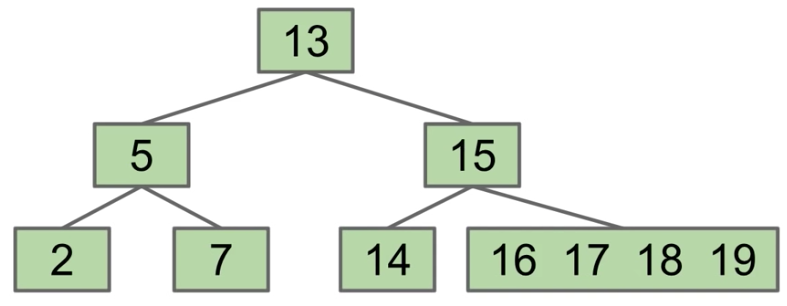
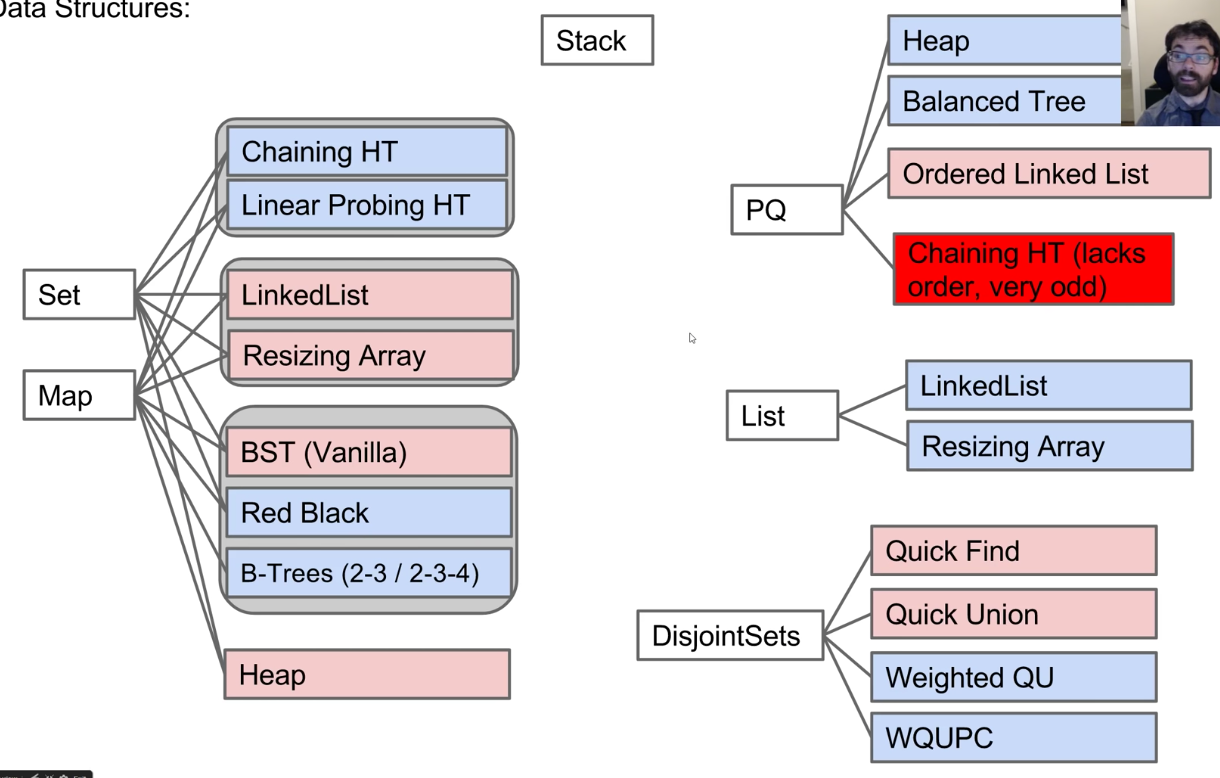
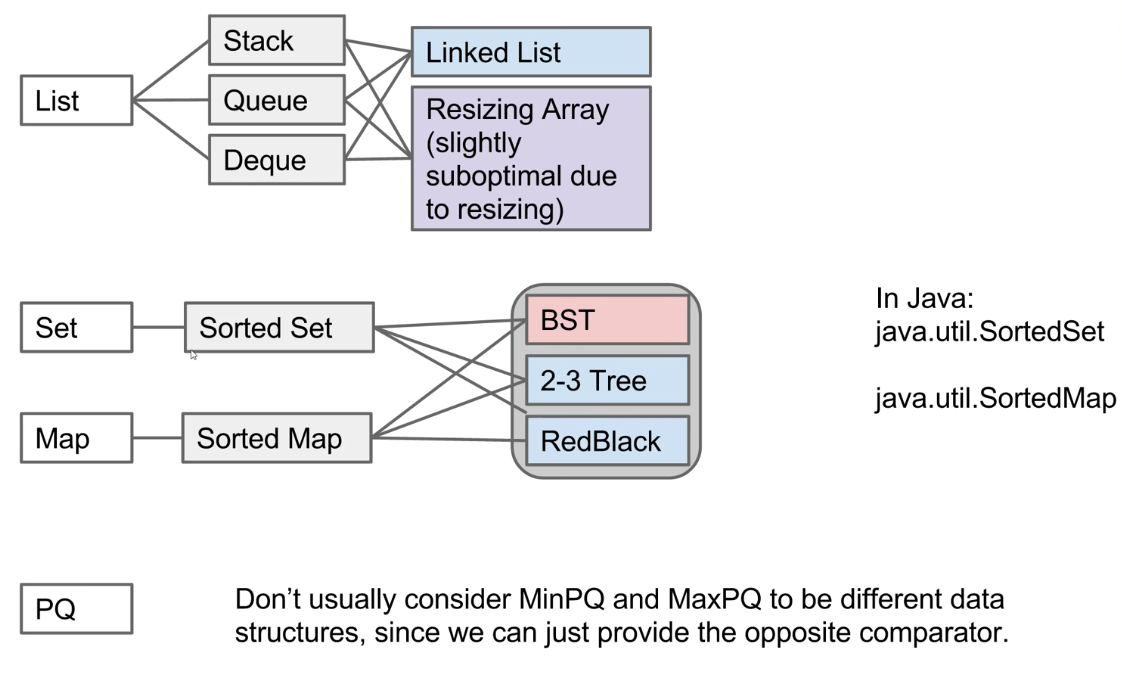
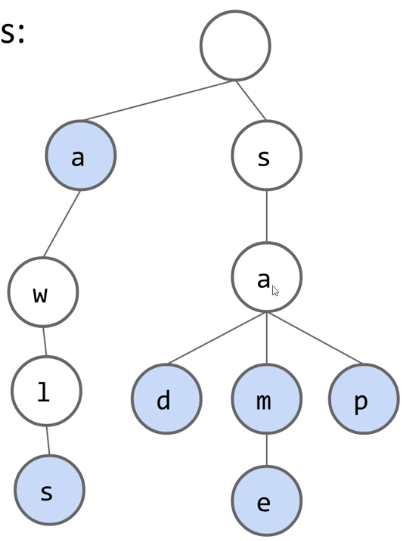
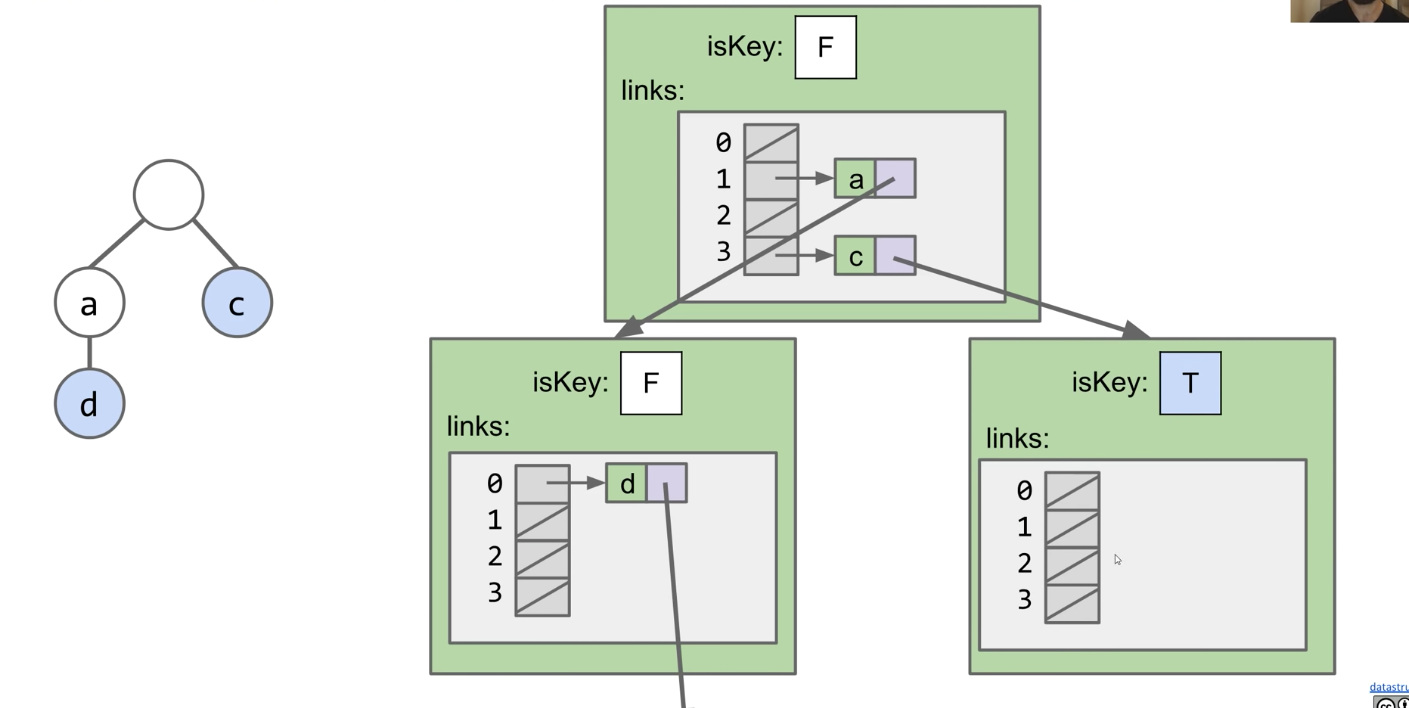
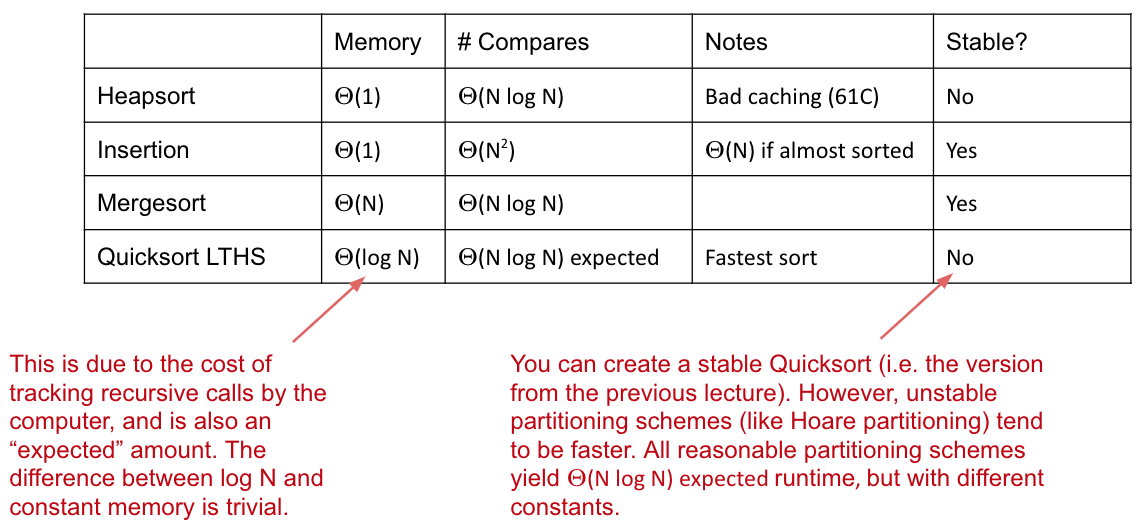
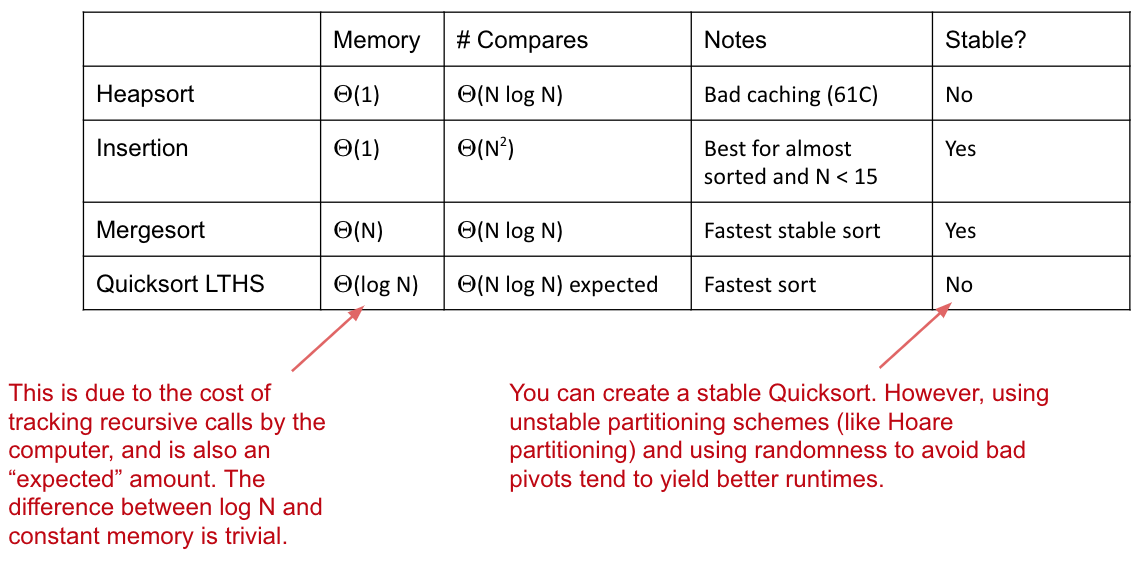
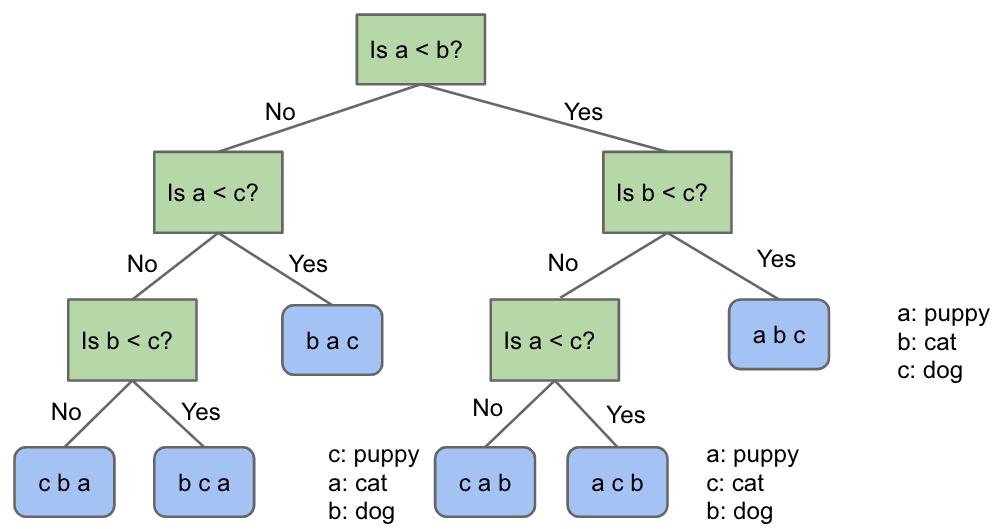
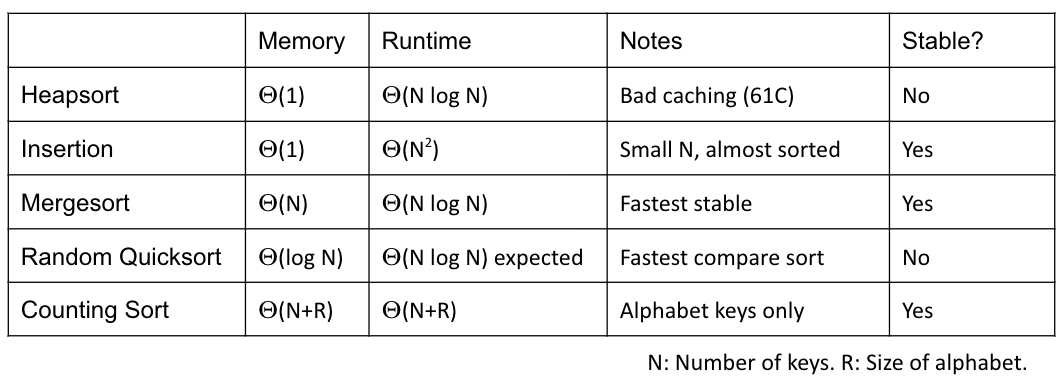
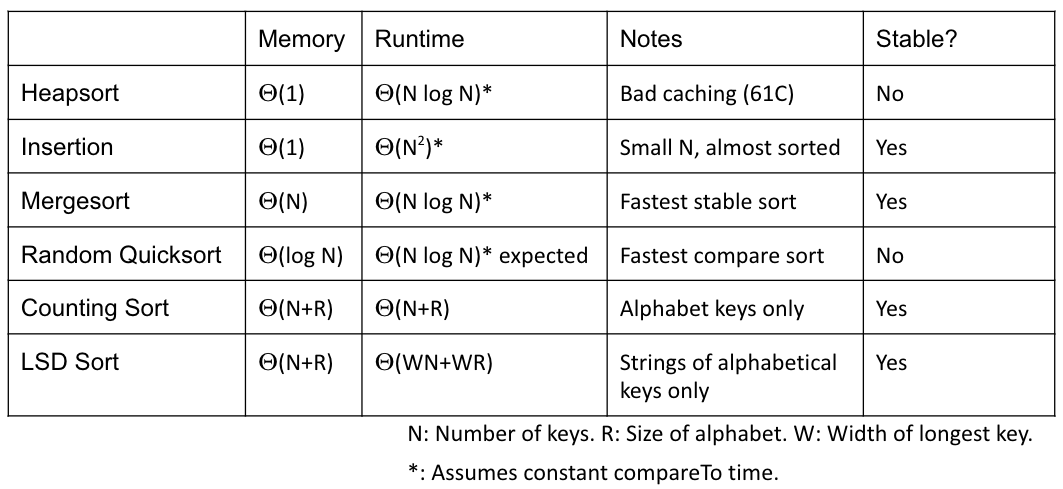
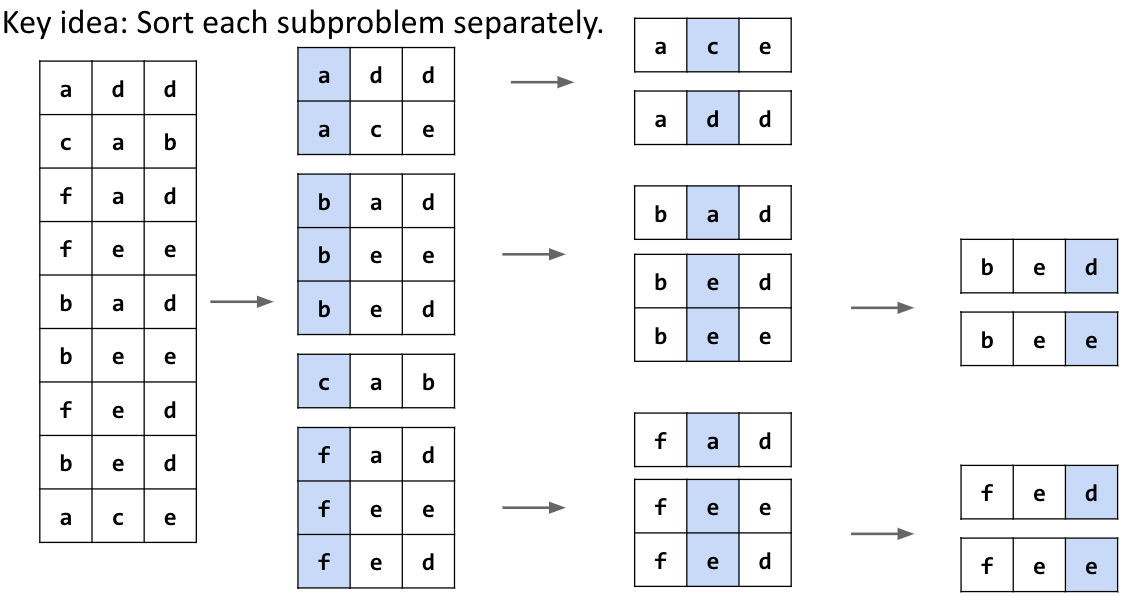
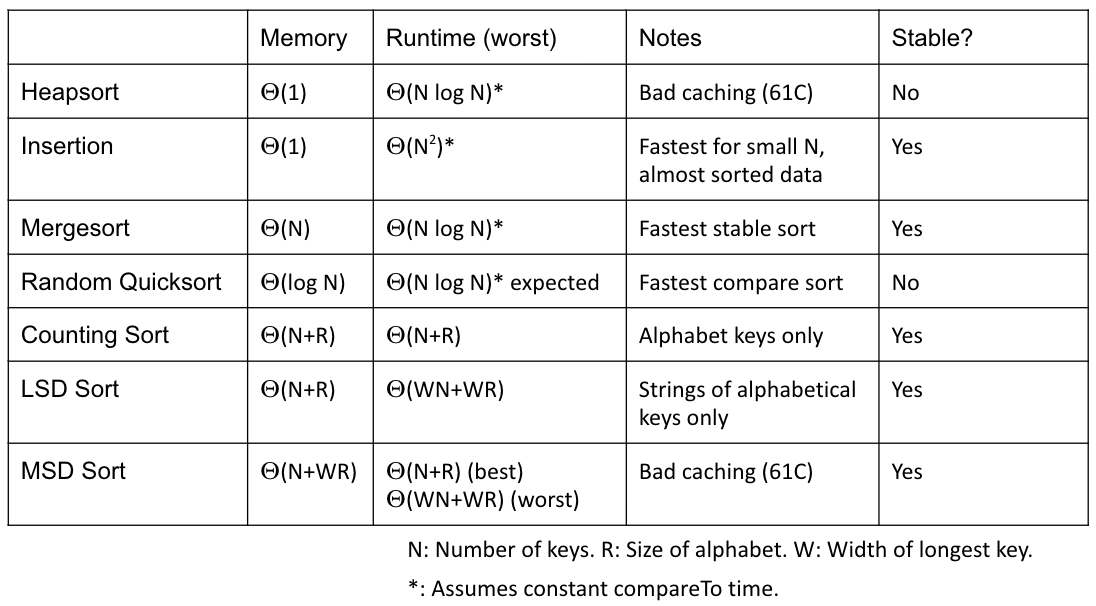
CS 61B contains content regarding data structures (e.g. lists, queues, trees, etc.) and algorithms for sorting and searching. The course also offers an introduction to the Java programming language. Below are the notes that I compiled from when I took CS 61B at UC Berkeley.
# In Python
print("hello world")
// In Java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("hello world");
}
}
// Output:
hello world
In Java, all code must be part of a class
Classes are defined with public class CLASSNAME
We use { } to delineate the beginning and ending of things
We must end lines with a semicolon
The code we want to run must be inside public static void main(String[] args)
# In Python
x = 0
while x < 10:
print(x)
x = x + 1
// In Java
public class HelloNumbers {
public static void main(String[] args) {
int x = 0; // Must declare variables, variable types can never change
while (x < 10) {
System.out.println(x);
x = x + 1;
}
}
}
Before Java variables can be used, they must be declared
Java variables must have a specific type
Java variable types can never change
Types are verified before the code even runs!!!
# In Python
def larger(x, y):
"""Returns the larger of x and y"""
if (x > y):
return x
return y
print (larger(-5, 10))
// In Java
public class LargerDemo {
/** Returns the larger of x and y. */
public static larger(int x, int y) {
if (x > y) {
return x;
}
return y;
}
public static void main(String[] args) {
System.out.println(larger(-5, 10));
}
}
Functions must be declared as part of a class in Java. A function that is part of a class is called a "method". So in Java, all functions are methods.
To define a function in Java, we use "public static". We will see alternate ways of defining functions later.
ALL parameters of a function must have a declared type, and the return value of a function must have a declared type.
Functions in Java return only one value!
Java and Object Orientation
Java is an object oriented language with strict requirements:
Every Java file must contain a class declaration
All code lives inside a class, even helper functions, global constants, etc.
To run a java program, you typically define a min method using public static void main(String[] args)
Java and Static Typing
Java is statically typed!
All variables, parameter,s and methods must have a declared type
That type can never change
Expressions also have a type
The compiler checks that all the types in your program are compatible before the program ever runs!
This is unlike Python, where type checks are performed DURING execution
Reflections on Static Typing
The Good:
Catches certain types of errors, making debugging easier
Type errors can (almost) never occur on the end user's computer
Makes it easier to read and reason about code
Code can run more efficiently, e.g. no need to do expensive runtime type checks
The Bad:
Code is more verbose
Code is less general (functions can only be applied to inputs of certain types)
There is a way around this in Java (generics)
Welcome to 61B 2019
What is 61B About?
Writing code that runs efficiently
Good algorithms
Good data structures
Writing code efficiently
Designing, building, testing, and debugging large programs
Use of programming tools
git, IntelliJ, JUnit
Java
Why Study Algorithms or Data Structures?
Daily life is supported by them
Why Study Algorithms or Data Structures?
Major driver of current progress of our civilization
Self-driving cars
AlphaGo
To become a better programmer
Being an efficient programmer means using the right data structures and algorithms for the job
Why Study Algorithms or Data Structures?
To understand the universe. Science is increasingly about simulation and complex data analysis rather than simple observations and clean equations.
.class file has been type checked. Distributed code is safer.
.class files are 'simpler' for the machine to execute. Distributed code is faster.
Minor benefit: Protects your intellectual property. No need to give out source.
Defining and Instantiating Classes
/** Dog.java file */
public class Dog {
public static void makeNoise() {
System.out.println("Bark!");
}
}
/** Can't be run directly, no main method */
/** DogLauncher.java file */
/** The DogLauncher class will test drive the Dog class */
public class DogLauncher {
public static void main(String[] args) {
Dog.makeNoise();
}
}
$ java DogLauncher
Bark!
Dog
Every method is associated with some class
To run a class, we must define a main method
Not all classes have a main method!
Object Instantiation
We could create a separate class for every single dog out there, but his is going to get redundant very quickly
Classes can contain not just functions (aka methods) but also data
Classes can be instantiated as objects
We'll create a single Dog class, and then create instances of this Dog
This class provides a blueprint that all Dog objects will follow
public class Dog {
public int weightInPounds; // An instance variable
/** One integer constructor for dogs. */
public Dog(int w) { // Constructor (similar to __init__)
weightInPounds = w;
}
public void makeNoise() { // Non-static method, instance method
if (weightInPounds < 10) {
System.out.println("yip!");
} else if (weightInPounds < 30) {
System.out.println("bark.");
} else {
System.out.println("wooooof!");
}
}
}
/** DogLauncher.java file */
/** The DogLauncher class will test drive the Dog class */
public class DogLauncher {
public static void main(String[] args) {
Dog smallDog; // Declaration of a Dog instance
new Dog(20); // Instantiation of a Dog instance
smallDog = new Dog(5); // Instantiation and Assignment
Dog mediumDog = new Dog(25); // Declaration, Instantiation, and Assignment
d.makeNoise(); // Invocation of the 25 lb Dog's makeNoise method
}
}
$ java DogLauncher
bark.
Defining a Typical Class (Terminology)
Instance variable: Can have as many of these as you want
Constructor: Similar to a method (but not a method), determines how to instantiate the class
Non-static method: a.k.a., instance method. Idea: If the method is going to be invoked by an instance of the class, then it should be non-static
Roughly speaking: If the method needs to use "my instance variables", the method must be non-static
Arrays of Objects
To create an array of objects:
First use the new keyword to create the array
Then use new again for each object you want to put in the array
Dog[] dogs = new Dog[2]; // Creates an array of Dogs of size 2
dogs[0] = new Dog(8);
dogs[1] = new Dog(20);
dogs[0].makeNoise(); // Yipping occurs
Static vs Instance Methods
Static vs Non-static
Key differences between static and non-static (a.k.a. instance) methods
Static methods are invoked using the class name, e.g. Dog.makeNoise();
Instance methods are invoked using an instance name, e.g. maya.makeNoise();
Static methods can't access "my" instance variables, because there is no "me"
Why Static Methods?
Some classes are never instantiated. For example, Math.
x = Math.round(5.6);
Sometimes, classes may have a mix of static and non-static methods
public class Dog {
public int weightInPounds; // An instance variable
/** A static variable that applies to all dog instances */
public static String binomen = "Canis familiaris";
/** One integer constructor for dogs. */
public Dog(int w) { // Constructor (similar to __init__)
weightInPounds = w;
}
public void makeNoise() { // Non-static method, instance method
if (weightInPounds < 10) {
System.out.println("yip!");
} else if (weightInPounds < 30) {
System.out.println("bark.");
} else {
System.out.println("wooooof!");
}
}
public static Dog maxDog(Dog d1, Dog d2) {
if (d1.weightInPounds > d2.weightInPounds) {
return d1;
}
return d2;
}
public Dog maxDog(Dog d2) {
if (this.weightInPounds > d2.weightInPounds) {
return this;
}
return d2;
}
}
public class DogLauncher {
public static void main(String[] args) {
Dog d = new Dog(15);
Dog d2 = new Dog(100);
Dog bigger = Dog.maxDog(d, d2);
bigger.makeNoise();
Dog bigger2 = d.maxDog(d2);
bigger2.makeNoise();
System.out.println(d.binomen);
System.out.println(Dog.binomen);
}
}
$ java DogLauncher
woooooof!
woooooof!
Canis familiaris
Canis familiaris
Static vs. Non-static
A class may have a mix of static and non-static members
A variable or method defined in a class is also called a member of that class
Static members are accessed using class name, e.g. Dog.binomen;
Non-static members cannot be invoked using class name
Static methods must access instance variables via a specific instance of the class, e.g. d2
public static void main(String[] args)
We already know what public, static, void means
One Special Role for String: Command Line Arguments
public class ArgsDemo {
/** Prints out the -th command line argument. */
public static void main(String[] args) {
System.out.println(args[0]);
}
}
$ java ArgsDemo hello some args
hello
ArgsSum Exercise
public class ArgsSum {
public static void main(String[] args) {
int N = args.length;
int i = 0;
int sum = 0;
while (i < N) {
sum = sums + Integer.parseInt(args[i]);
i = i + 1;
}
}
}
Using Libraries (e.g. StdDraw, In)
Java Libraries
There are tons of Java libraries out there
In 61B, we will provide all needed libraries including:
Built-in Java libraries
Princeton standard library
As a programmer, you'll want to leverage existing libraries whenever possible
Saves you the trouble of writing code
Existing widely using libraries are (probably) will probably be less buggy
... but you'll have to spend some time getting acquainted with the library
Best ways to learn how to use an unfamiliar library:
Find a tutorial online
Read the documentation for the library (Java docs)
Look at example code snippets that use the library
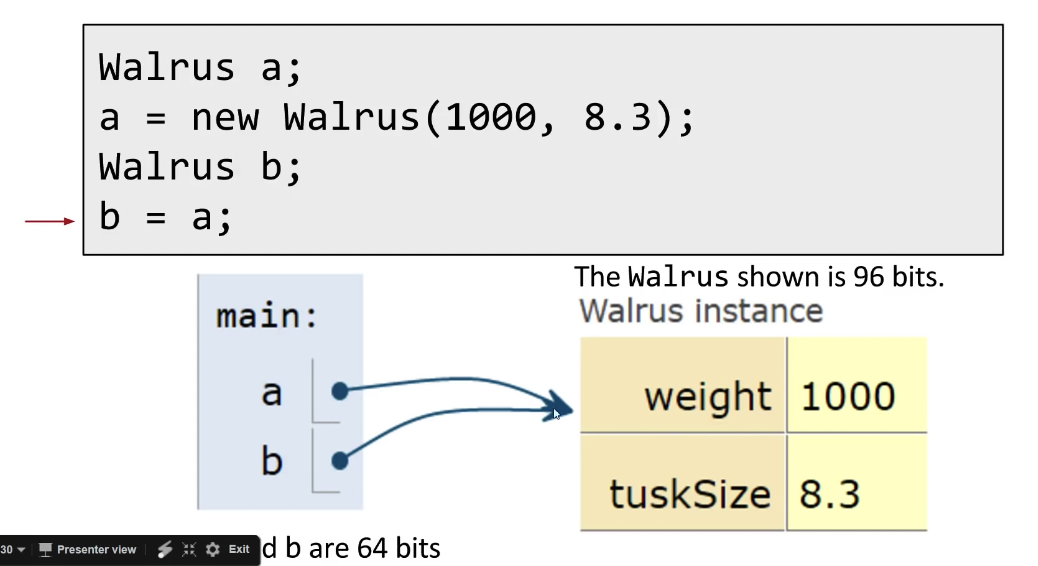
Walrus a = new Walrus(1000, 8.3);
Walrus b;
b = a;
b.weight = 5;
System.out.println(a);
System.out.println(b);
Result:
5
5
The change to b will affect a
int x = 5;
int y;
y = x;
x = 2;
System.out.println(x);
System.out.println(y);
Result:
2
5
The change to x will not affect y
Bits
Your computer stores information in "memory"
Information is stored in memory as a sequence of ones and zeros
Example: 72 stored as 01001000
Example: Letter H stored as 01001000 (same as the number 72)
Example: True stored as 00000001
Each Java type has a different way to interpret the bits:
8 primitive types in Java:
byte
short
int
long
float
double
boolean
char
Declaring a Variable (simplified)
int x;
double y;
x = -1431195969;
y = 567213.112
When you declare a variable of a certain type in Java:
Your computer sets aside exactly enough bits to hold a thing of that type
Ex: Declaring an int sets aside a "box" of 32 bits
Ex: Declaring a double sets aside a box of 64 bits
Java creates an internal table that maps each variable name to a location
Java does NOT write anything into the reserved boxes
For safety, Java will not let access a variable that is uninitialized
Simplified Box Notation
We'll use simplified box notation
Instead of writing memory box contents in binary, we'll write them in human readable code
The Golden Rule of Equals (GRoE)
Given variables y and x:
y = xcopies all the bits from x into y
Reference Types
Reference Types
There are 8 primitive types in Java
Everything else, including arrays, is a reference type
Class Instantiations
When we instantiate an Object
Java first allocates a box of bits for each instance variable of the class and fills them with a default value (e.g. 0, null)
The constructor then usually fills every box with some other value
public class Walrus {
public int weight;
public double tuskSize;
public Walrus(int w, double ts) {
weight = w;
tuskSize = ts;
}
}
Can think of new as returning the address of the newly created object
Addresses in Java are 64 bits
Example: If object is created in memory location 111111111, then new returns 1111111111
Reference Type Variable Declarations
When we declare a variable of any reference type:
Java allocates exactly a box of size 64 bits, no matter what type of object
These bits can be either set to:
Null (all zeros)
Walrus someWalrus;
someWalrus = null;
The 64 bit "address" of a specific instance of that class (returned by new)
Walrus someWalrus;
someWalrus = new Walrus(1000, 8.3);
The 64 bit addresses are meaningless to us as humans, so we'll represent:
All zero addresses with "null"
Non-zero addresses as arrows
Basically, the box-and-pointer notation from CS 61A
Reference Types Obey the Golden Rule of Equals
Just as with primitive types, the equals sign copies the bits
In terms of our visual metaphor, we "copy" the arrow by making the arrow in the b box point at the same instance as a
a and b are 64 bits
Parameter Passing
The Golden Rule of Equals (and Parameter Passing)
Given variables b and a:
b = a copies all the bits from a into b
Passing parameters obeys the same rule: Simply copy the bits to the new scope (parameters are "passed by value")
public static double average(double a, double b) {
return (a + b) / 2;
}
public static void main(String[] args) {
double x = 5.5;
double y = 10.5;
double avg = average(x, y);
}
The Golden Rule: Summary
There are - types of variables in Java:
8 primitive types
The 9th type is references to Objects (an arrow). References may be null
In box-and-pointer notation, each variable is drawn as a labeled box and values are shown in the box
Addresses are represented by arrows to object instances
The golden rule:
b = acopies the bits from a into b
Passing parameters copies the bits
Instantiation of Arrays
Declaration and Instantiation of Arrays
Arrays are also Objects. As we've seen, objects are instantiated using the new keyword
int[] x = new int[]{0, 1, 2, 95, 4};
int[] a;: Declaration
Declaration creates a 64 bit box intended only for storing a reference to an int array. No object is instantiated
new int[]{0, 1, 2, 95, 4};: Instantiation
Instantiates a new Object, in this case an int array
Object is anonymous!
Assignment of Arrays
int[] x = new int[]{0, 1, 2, 95, 4};
Creates a 64 bit box for storing an int array address
Creates a new Object, in this case an int array (Instantiation)
Puts the address of this new Object into the 64 bit box named a (assignment)
Note: Instantiated objects can be lost!
If we were to reassign a to something else, we'd never be able to get the original Object back!
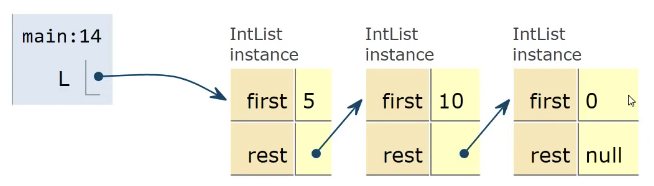
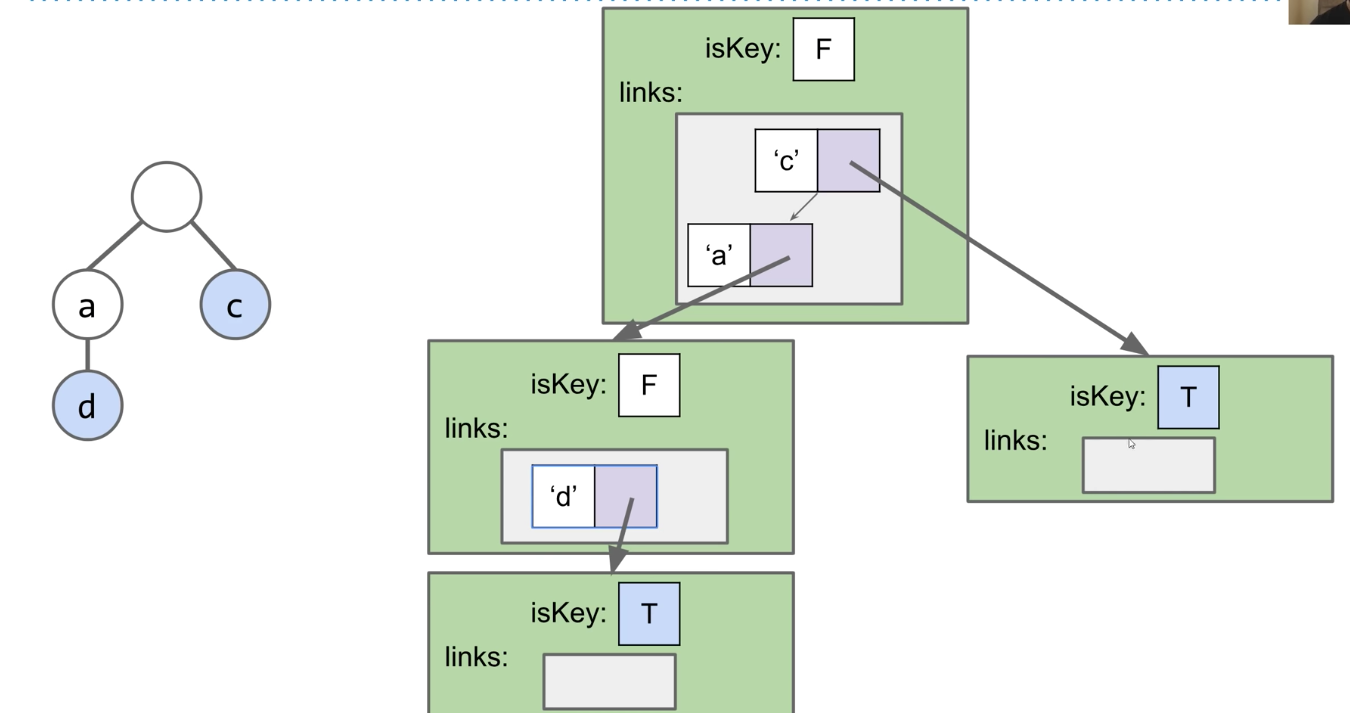
IntList and Linked Data Structures
IntList
Let's define an InstList as an object containing two member variables:
int first;
IntList rest;
public class IntList {
public int first;
public IntList rest;
public IntList(int f, IntList r) {
first = f;
rest = r;
}
public static void main(String[] args) {
IntList L = new IntList(15, null);
L = new IntList(10, L);
L = new IntList(5, L);
}
}
IntList
And define two versions of the same method:
size()
iterativeSize()
public class IntList {
public int first;
public IntList rest;
public IntList(int f, IntList r) {
first = f;
rest = r;
}
public int size() {
// Return the size of the list using... recursion!
if (rest == null) {
return 1;
}
return 1 + this.rest.size();
}
public int iterativeSize() {
// Return the size of the list using no recursion
IntList p = this;
int totalSize = 0;
while (p != null) {
totalSize += 1;
p = p.rest;
}
return totalSize;
}
public static void main(String[] args) {
IntList L = new IntList(15, null);
L = new IntList(10, L);
L = new IntList(5, L);
}
}
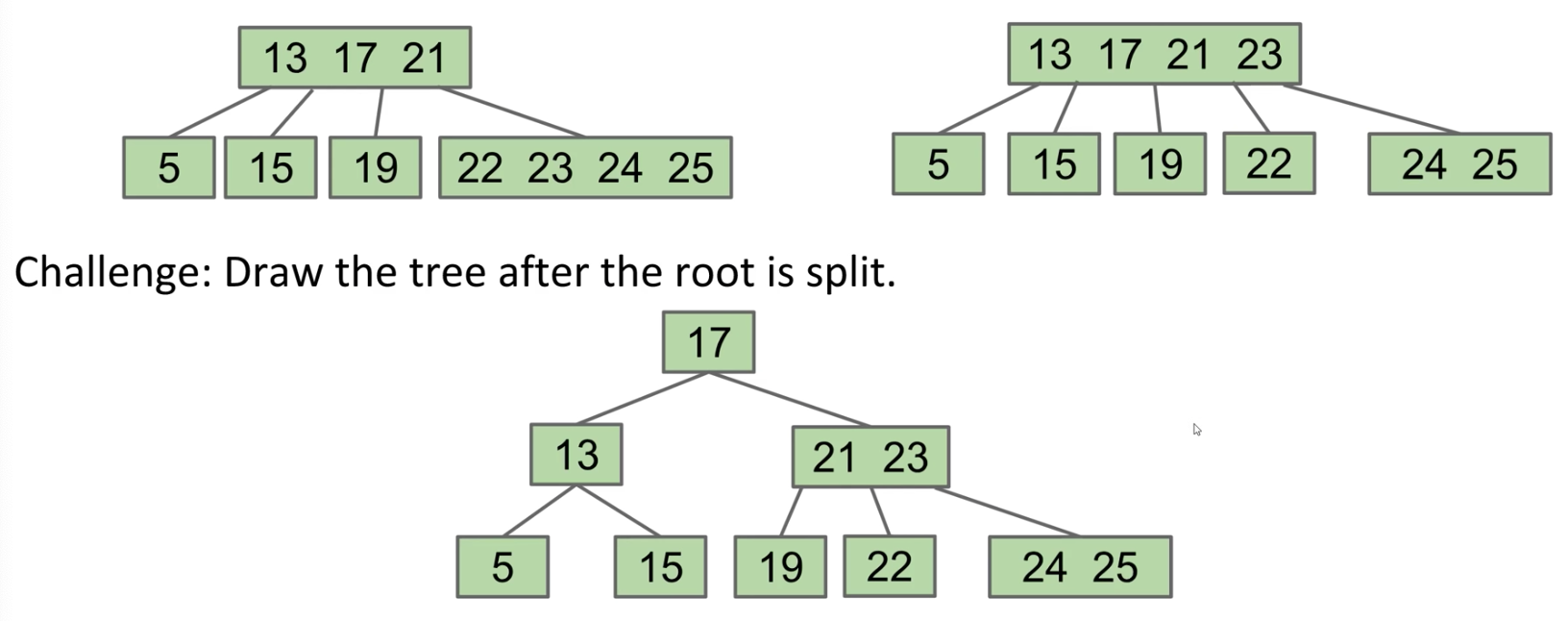
Challenge
Write a method int get(int i) that returns the ith item in the list
Assume the item exists
Front item is the 0th item
public class IntList {
public int first;
public IntList rest;
public IntList(int f, IntList r) {
first = f;
rest = r;
}
public int size() {
// Return the size of the list using... recursion!
if (rest == null) {
return 1;
}
return 1 + this.rest.size();
}
public int iterativeSize() {
// Return the size of the list using no recursion
IntList p = this;
int totalSize = 0;
while (p != null) {
totalSize += 1;
p = p.rest;
}
return totalSize;
}
public int get(int i) {
// Returns the ith item of this IntList
if (i == 0) {
return first;
}
return rest.get(i - 1);
}
public static void main(String[] args) {
IntList L = new IntList(15, null);
L = new IntList(10, L);
L = new IntList(5, L);
}
}
public class IntList {
public int first;
public IntList rest;
public IntList(int f, IntList r) {
first = f;
rest = r;
}
}
While functional, "naked" linked lists like the one above are hard to use
Users of this class are probably going to need to know references very well, and be able to think recursively. Let's make our users' lives easier
Improvement #1: Rebranding and Culling
public class IntNode {
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
Improvement #2: Bureaucracy
public class IntNode {
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
// An SLList is a list of integers, which hides the terrible truth of the nakedness within
public class SLList {
public IntNode first;
public SLList(int x) {
first = new IntNode(x, null);
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList(10);
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
int x = L.getFirst();
}
}
SLList is easier to instantiate (no need to specify null)
The Basic SLList and Helper IntNode Class
While functional, "naked" linked lists like the IntList class are hard to use
Users of IntList need to know Java references well, and be able to think recursively
SLList is much simpler to use
A Potential SLList Danger
SLList L = new SLList(15);
L.addFirst(10);
L.first.next.next = L.first.next;
public class SLList {
private IntNode first;
public SLList(int x) {
first = new IntNode(x, null);
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList(10);
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
int x = L.getFirst();
}
}
Use the private keyword to prevent code in other classes from using members (or constructors) of a class
Why Restrict Access?
Hide implementation details from users of your class
Less for user of class to understand
Safe for you to change private methods (implementation)
Despite the term 'access control':
Nothing to do with protection against hackers, spies, or other evil entities
Improvement #4: Nesting a Class
public class SLList {
private static class IntNode { // static: never looks outwards
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode first;
public SLList(int x) {
first = new IntNode(x, null);
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList(10);
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
int x = L.getFirst();
}
}
Could have made IntNode private if we wanted to
Why Nested Classes?
Nested Classes are useful when a class doesn't stand on its own and is obviously subordinate to other classes
Make the nested class private if other classes should never use the nested class
Static Nested Classes
If the nested class never uses any instance variables or methods of the outside class, declare it static
Static classes cannot access outer class's instance variables or methods
Results in a minor savings of memory
Adding More SLList Functionality
To motivate our remaining improvements, ad to give more functionality to our SLList class, let's add:
.addLast(int x)
.size()
public class SLList {
private static class IntNode { // static: never looks outwards
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode first;
public SLList(int x) {
first = new IntNode(x, null);
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
// Adds an item to the end of the list
public void addLast(int x) {
IntNode p = first;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
// Returns the size of the list that starts at IntNode p
private static int size(IntNode p) {
if (p.next == null) {
return 1;
}
return 1 + size(p.next);
}
public int size() {
return size(first);
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList(10);
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
L.addLast(20);
System.out.println(L.size())
}
}
Efficiency of Size
How efficient is size?
Suppose size takes 2 seconds on a list of size 1000
How long will it take on a list of size 1000000?
2000 seconds!
Improvement #5: Fast size()
Your goal:
Modify SLList so that the execution time of size() is always fast (i.e. independent of the size of the list)
public class SLList {
private static class IntNode { // static: never looks outwards
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode first;
private int size;
public SLList(int x) {
first = new IntNode(x, null);
size = 1;
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
size += 1;
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
// Adds an item to the end of the list
public void addLast(int x) {
size += 1;
IntNode p = first;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
public int size() {
return size;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList(10);
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
L.addLast(20);
System.out.println(L.size())
}
}
Solution: Maintain a special size variable that caches the size of the list
Caching: putting aside data to speed up retrieval
TANSTAAFL: There ain't no such thing as a free lunch
But spreading the work over each add call is a net win in almost any case
The SLList class allows us to store meta information about the entire list, e.g. size
Improvement #6a: Representing the Empty List
public class SLList {
private static class IntNode { // static: never looks outwards
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode first;
private int size;
// Creates an empty SLList
public SLList() {
first = null;
size = 0;
}
public SLList(int x) {
first = new IntNode(x, null);
size = 1;
}
// Adds x to the front of the list
public void addFirst(int x) {
first = new IntNode(x, first);
size += 1;
}
// Returns the first item in the list
public int getFirst() {
return first.item;
}
// Adds an item to the end of the list
public void addLast(int x) {
size = size + 1;
if (first == null) {
first = new IntNode(x, null);
return;
}
IntNode p = first;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
public int size() {
return size;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList();
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
L.addLast(20);
System.out.println(L.size())
}
}
Tip for Being a GOod Programmer: Keep Code Simple
As a human programmer, you only have so much working memory
You want to restrict the amount of complexity in your life!
Simple code is (usually) good code
Special cases are not "simple"
addLast's Fundamental Problem
The fundamental problem:
The empty list has a null first, can't access first.next
Our fix is a bit ugly:
Requires a special case
More complex data structures will have many more special cases
How can we avoid special cases?
Make all SLLists (even empty) the "same"
Improvement #6b: Representing the Empty List Use a Sentinel Node
Create a special node that is always there! Let's call it a "sentinel node"
The empty list is just the sentinel node
A list with 3 numbers has a sentinel node and 3 nodes that contain real data
Let's try reimplementing SLList with a sentinel node
public class SLList {
private static class IntNode { // static: never looks outwards
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
// The first item (if it exists) is at sentinel.next
private IntNode sentinel;
private int size;
// Creates an empty SLList
public SLList() {
sentinel = new IntNode(69, null);
size = 0;
}
public SLList(int x) {
sentinel = new IntNode(69, null);
sentinel.next = new IntNode(x, null);
size = 1;
}
// Adds x to the front of the list
public void addFirst(int x) {
sentinel.next = new IntNode(x, sentinel.next);
size = size + 1;
}
// Returns the first item in the list
public int getFirst() {
return sentinel.next.item;
}
// Adds an item to the end of the list
public void addLast(int x) {
size = size + 1;
IntNode p = sentinel;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
public int size() {
return size;
}
public static void main(String[] args) {
// Creates a list of one integer, namely 10
SLList L = new SLList();
L.addFirst(10); // Adds 10 to front of list
L.addFirst(5); // Adds 5 to front of list
L.addLast(20);
System.out.println(L.size())
}
}
Sentinel Node
The sentinel node is always there for you
Notes:
I've renamed first to be sentinel
sentinel is never null, always points to sentinel node
Sentinel node's item needs to be some integer, but doesn't matter what value we pick
Had to fix constructors and methods to be compatible with sentinel nodes
addLast (with Sentinel Node)
Bottom line: Having a sentinel simplifies our addLast method
No need for a special case to check if sentinel is null
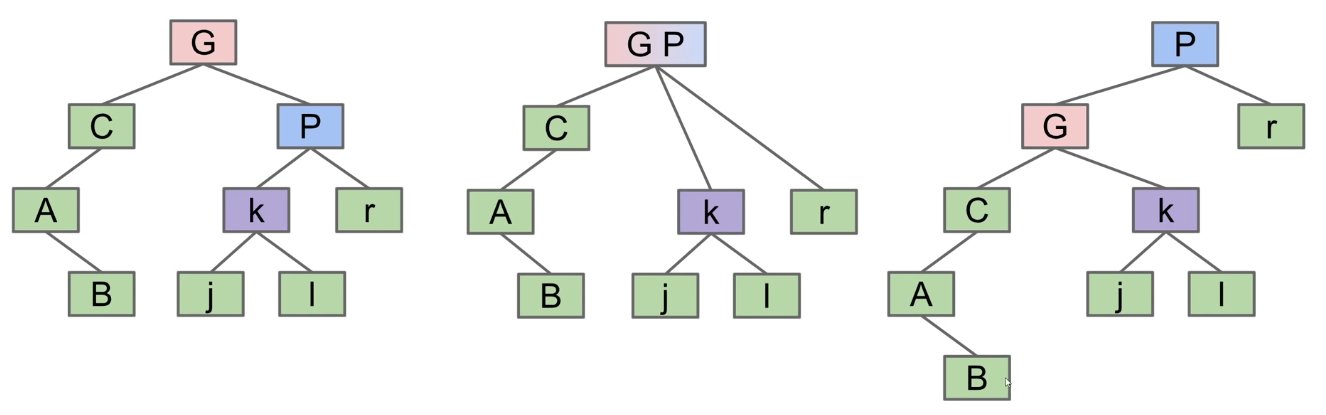
Invariants
An invariant is a condition that is guaranteed to be true during code execution (assuming there are no bugs in your code)
An SLList with a sentinel node has at least the following invariants
The sentinel reference always points to a sentinel node
The first node is always at sentinel.next
The size variable is always the total number of items that have been added
Invariants make it easier to reason about code
Can assume they are true to simplify code (e.g. addLast doesn't need to worry about nulls)
Inserting at the back of an SLList is much slower than the front
Improvement #7: Fast addLast
Suppose we want to support add, get, and remove operations, will having a last pointer result for fast operations on long lists?
Why a Last Pointer Isn't Enough
.last is not enough
The remove operation will still be slow. Requires setting the second to last node's pointer to null, and last to the second to last node
Improvement #7: .last and ???
We added .last. What other changes might we make so that remove is also fast?
Add backwards links from every node
This yields a "doubly linked list" or DLList, as opposed to our earlier "singly linked list" or SLList
Doubly Linked Lists (Naive)
Reverse pointers allow all operations (add, get, remove) to be fast
We call such a list a "doubly linked list" or DLList
This approach has an annoying special case: last sometimes points to the sentinel, and sometimes points at a "real" node
Doubly Linked Lists (Double Sentinel)
One solution: have two sentinels
One that is always at the front and one that is always at the back
Doubly Linked Lists (Circular Sentinel)
A single sentinel is both at the front and and the back
Improvement #8: Fancier Sentinel Nodes
While fast, adding .last and .prev introduces lots of special cases
To avoid these, either:
Add an additional sentBack sentinel at the end of the list
Make your linked list circular (highly recommended for project 1), with a single sentinel in the middle
Generic Lists
Integer Only Lists
One issue with our list classes: They only support integers
public class SLList<LochNess> {
private class StuffNode {
public LochNess item;
public StuffNode next;
public StuffNode(LochNess i, StuffNode n) {
item = i;
next = n;
}
}
private StuffNode first;
private int size;
...
...
...
}
public class SLListLauncher {
public static void main(String[] args) {
SLList<String> s1 = new SLList<>("bone");
s1.addFirst("thugs");
}
}
SLists
Java allows us to defer type selection until declaration
Generics
Rules for project 1
In the .java file implementing your data structure, specify your "generic type" only once at the very top of the file
In the .java files that use your data structure, specify desired type once:
Write out desired type during declaration
Use the empty diamond operator <> during instantiation
When declaring or instantiating your data structure, use the reference type:
int: Integer
double: Double
char: Character
boolean: Boolean
long: Long
Array Overview
Getting Memory Boxes
To store information, we need memory boxes, which we can get in Java by declaring variables or instantiating objects. Examples:
int x;
Walrus w1;
Walrus w2 = new Walrus(30, 5.6);
Arrays are a special kind of object which consists of a numbered sequence of memory boxes
To get ith item of array A, use A[i]
Unlike class instances which have named memory boxes
Arrays
Arrays consist of:
A fixed integer length
A sequence of N memory boxes where N=length such that:
All of the boxes hold the same type of value (and have the same # of bits)
The boxes are numbered 0 through length-1
Like instances of class:
You get one reference when it's created
If you reassign all variables containing that reference, you can never get the array back
Unlike classes, arrays do not have methods
Arrays
Like classes, arrays are instantiated with new
Three valid notations:
y = new int[3];
Creates array containing 3 int boxes (32 x 3 = 96 bits total)
Each container gets a default value
The default value for int is 0
The default value for String is null (holds string references)
x = new int[]{1, 2, 3, 4, 5};
int[] w = {9, 10, 11, 12, 13};
Can omit the new if you are also declaring a variable
All three notations create an array, which we saw on the last side comprises:
A length field
A sequence of No boxes where N = length
Array Basics:
int[] z = null;
int[] x, y;
x = new int[]{1, 2, 3, 4, 5};
y = x;
x = new int[]{-1, 2, 5, 4, 99};
y = new int[3];
z = new int[0];
int xL = x.length;
String[] s = new String[6];
s[4] = "ketchup";
s[x[3] - x[1]] = "muffins";
int[] b = {9, 10, 11};
System.arraycopy(b, 0, x, 3, 2);
Array Copy
Two ways to copy arrays:
Item by item using a loop
Using arraycopy. Takes 5 parameters:
Source array
Start position in source
Target array
Start position in target
Number to copy
System.arraycopy(b, 0, x, 3, 2);
(In Python): x[3:5] = b[0:2]
arraycopy is (likely to be) faster, particularly for larger arrays. Comre compact code
Code is (arguably) harder to read
2D Arrays
Arrays of Array Addresses
int[][] pascalsTriangle;
pascalsTriangle = new int[4][];
int[] rowZero = pascalsTriangle[0];
pascalsTriangle[0] = new int[]{1};
pascalsTriangle[1] = new int[]{1, 1};
pascalsTriangle[2] = new int[]{1, 2, 1};
pascalsTriangle[3] = new int[]{1, 3, 3, 1};
int[] rowTwo = pascalsTriangle[2];
rowTwo[1] = -5;
int[][] matrix;
matrix = new int[4][];
matrix = new int[4][4];
int[][] pascalAgain = new int[][]{{1}, {1, 1}, {1, 2, 1}, {1, 3, 3, 1}};
Syntax for arrays of arrays can be a bit confounding. You'll learn through practice
int[][] pascalsTriangle;
Array of int array references
pascalsTriangle = new int[4][];
Create four boxes, each can store an int array reference
pascalsTriangle[2] = new int[]{1, 2, 1};
Create a new array with three boxes, storing integers 1, 2, 1, respectively. Store a reference to this array in pascalsTriangle in box #2
matrix = new int[4][];
Creates 1 total array
matrix = new int[4][4];
Creates 5 total arrays
Arrays vs. Classes
Arrays vs. Classes
Arrays and Classes can both be used to organize a bunch of memory boxes
Array boxes are accessed using [] notation
Class boxes are accessed using dot notation
Array boxes must all be of the same type
Class boxes may be of different types
Both have a fixed number of boxes
Array indices can be computed at runtime
Class member variable names CANNOT be computed and used at runtime
Dot notation does not work
[] notation also does not work
Another view
The only (easy) way to access a member of a class is with hard-coded dot notation
int k = x[indexOfInterest];
double m = p.fieldOfInterest; // Won't work
double z = p[fieldOfInterest]; // Won't work
// No (sane) way to use field of interest
double w = p.mass; // Works fine
Through various improvements, we made all of the following operations fast:
addFirst, addLast
getFirst, getLast
removeFirst, removeLast
Arbitrary Retrieval
Suppose we added get(int i), which returns the ith item from the list
Why would get be slow for long lists compared to getLast()? For what inputs?
Have to scan to desired position. Slow for any i not near the sentinel node
How to fix this?
For now: We'll take a different tack: Using an array instead (no links!)
Naive Array Lists
Random Access in Arrays
Retrieval from any position of an array is very fast
Independent of array size
61C Preview: Ultra fast random access results from the fact that memory boxes are the same size (in bits)
Our Goal: AList.java
Want to figure out how to build an array version of a list:
In lecture we'll only do back operations
public class AList {
private int[] items;
private int size;
/** Creates an empty list. */
public AList() {
items = new int[100];
size = 0;
}
/** Inserts X into the back of the list */
public void addLast(int x) {
items[size] = x;
size = size + 1;
}
/** Returns the item from the back of the list. */
public int getLast() {
return items[size-1];
}
/** Gets the ith item from the List (0 is the front) */
public int get(int i) {
return items[i];
}
/** Returns the number of items in the list. */
public int size() {
return size;
}
}
Naive AList Code
AList Invariants:
The position of the next item to be inserted is always size
size is always the number of items in the AList
The last item in the list is always in position size - 1
Let's now discuss delete operations
The Abstract vs. the Concrete
When we removeLast(), which memory boxes need to change? To what?
When we removeLast(), which memory boxes need to change? To what?
Only size!
public class AList {
private int[] items;
private int size;
/** Creates an empty list. */
public AList() {
items = new int[100];
size = 0;
}
/** Inserts X into the back of the list */
public void addLast(int x) {
items[size] = x;
size = size + 1;
}
/** Returns the item from the back of the list. */
public int getLast() {
return items[size-1];
}
/** Gets the ith item from the List (0 is the front) */
public int get(int i) {
return items[i];
}
/** Returns the number of items in the list. */
public int size() {
return size;
}
/** Deletes item from back of the list and returns deleted item */
public int removeLast() {
int x = getLast();
items[size-1] = 0; // Not necessary to preserve invariants -> not necessary for correctness
size = size - 1;
return x;
}
}
Resizing Arrays
The Mighty AList
Key Idea: Use some subset of the entries of an array
What happens if we insert more than 100 items in AList? What should we do about it?
Array Resizing
When the array gets too full, e.g. addLast(11), just make a new array:
int[] a = new int[size+1];
System.arraycopy()
a[size] = 11;
items = a; size += 1;
We call this process "resizing"
Implementation
Let's implement the resizing capability
public class AList {
private int[] items;
private int size;
/** Creates an empty list. */
public AList() {
items = new int[100];
size = 0;
}
/** Resizes the underlying array to the target capacity */
private void resize(int capacity) {
int[] a = new int[capacity]
System.arraycopy(items, 0, a, 0, size);
items = a;
}
/** Inserts X into the back of the list */
public void addLast(int x) {
if (size == items.length) {
resize(size + 1);
}
items[size] = x;
size = size + 1;
}
/** Returns the item from the back of the list. */
public int getLast() {
return items[size-1];
}
/** Gets the ith item from the List (0 is the front) */
public int get(int i) {
return items[i];
}
/** Returns the number of items in the list. */
public int size() {
return size;
}
/** Deletes item from back of the list and returns deleted item */
public int removeLast() {
int x = getLast();
items[size-1] = 0; // Not necessary to preserve invariants -> not necessary for correctness
size = size - 1;
return x;
}
}
Basic Resizing Analysis
Runtime and Space Usage Analysis
Suppose we have a full array of size 100. If we can addLast two times, how many total array memory boxes will we need to create and fill?
Answer: 203
Array Resizing
Resizing twice requires us to create and fill 203 total memory boxes
Most boxes at any one time is 203
Runtime and Space Usage Analysis
Suppose we have a full array of size 100. If we call addLast until size = 1000, roughly how many total memory boxes will we need to create and fill?
Inserting 100,000 items requires rought 5,000,000,000 new containers
Computers operate at the speed of GHz
No huge surprise that 100,000 items took seconds
Our resizing for ALists is done in linear time
Making AList Fast
Fixing the Resizing Performance Bug
How do we fix this?
public class AList {
private int[] items;
private int size;
/** Creates an empty list. */
public AList() {
items = new int[100];
size = 0;
}
/** Resizes the underlying array to the target capacity */
private void resize(int capacity) {
int[] a = new int[capacity]
System.arraycopy(items, 0, a, 0, size);
items = a;
}
/** Inserts X into the back of the list */
public void addLast(int x) {
if (size == items.length) {
resize(size * 2); // A subtle fix!!!
}
items[size] = x;
size = size + 1;
}
/** Returns the item from the back of the list. */
public int getLast() {
return items[size-1];
}
/** Gets the ith item from the List (0 is the front) */
public int get(int i) {
return items[i];
}
/** Returns the number of items in the list. */
public int size() {
return size;
}
/** Deletes item from back of the list and returns deleted item */
public int removeLast() {
int x = getLast();
items[size-1] = 0; // Not necessary to preserve invariants -> not necessary for correctness
size = size - 1;
return x;
}
}
(Probably) Surprising Fact
Geometric resizing is much faster: Just how much better will have to wait
public void addLast(int x) {
if (size == items.length) {
resize(size * 2); // A subtle fix!!!
}
items[size] = x;
size = size + 1;
}
This is how Python lists are implemented
Performance Problem #2
Suppose we have a very rare situation occurs which causes us to:
Insert 1,000,000,000 items
Then remove 990,000,000 items
Our data structure will handle this spike of evens as well as it could, but afterwards there is a problem
Memory Efficiency
An AList should not only be efficient in time, but also efficient in space
Define the "usage ratio" R = size / items.length;
Typical solution: Half array size when R < 0.25
More details in a few weeks
Later we will consider tradeoffs between time and space efficiency for a variety of algorithms and data structures
Generic AList
There's a Problem
Generic arrays are not allowed :((
Here's our fix
public class AList<Item> {
private Item[] items;
private int size;
/** Creates an empty list. */
public AList() {
items = (Item[]) new Object[100];
size = 0;
}
/** Resizes the underlying array to the target capacity */
private void resize(int capacity) {
Item[] a = (Item[]) new Object[capacity]
System.arraycopy(items, 0, a, 0, size);
items = a;
}
/** Inserts X into the back of the list */
public void addLast(int x) {
if (size == items.length) {
resize(size * 2); // A subtle fix!!!
}
items[size] = x;
size = size + 1;
}
/** Returns the item from the back of the list. */
public Item getLast() {
return items[size-1];
}
/** Gets the ith item from the List (0 is the front) */
public Item get(int i) {
return items[i];
}
/** Returns the number of items in the list. */
public int size() {
return size;
}
/** Deletes item from back of the list and returns deleted item */
public Item removeLast() {
int x = getLast();
items[size-1] = null;
size = size - 1;
return x;
}
}
Generic ALists (similar to generic SLists)
When creating an array of references to Glorps:
(Glorp[]) new Object[cap];
Causes a compiler warning, which you should ignore
Why not just new Glorp[cap]
Will cause a "generic array creation" error
Nulling Out Deleted Items
Unlike integer based ALists, we actually want to null out deleted items
Java only destroys unwanted objects when the last reference has been lost
Keeping references to unneeded objects is sometimes called loitering
Running main and seeing if the code behaves as expected
The Autograder
In the real world, programmers believe their code works because of tests they write themselves
Knowing that it works for sure is usually impossible
This will be our new way
Sorting: The McGuffin for Our Testing Adventure
To try out this new way, we need a task to complete
Let's try to write a method that sorts arrays of Strings
The New Way
We will write our test for TestSort first
Ad Hoc Testing vs. JUnit
Ad Hoc Test
public class TestSort {
/** Test the Sort.sort method */
public static void testSort() {
String[] input = {"i", "have", "an", "egg"};
String[] expected = {"an", "egg", "have", "i"};
Sort.sort(input);
for (int i = 0; i < input.length; i += 1) {
if (!input[i].equals(expected[i])) {
System.out.println("Mismatch in position " + i);
return;
}
}
if (java.utils.Arrays.equals(input, expected)) {
System.out.println("Error! There seems to be a problem with Sort.sort.");
}
}
public static void main(String[] args) {
testSort();
}
}
JUnit: A Library for Making Testing Easier
Ad Hoc Testing is tedious, use JUnit library instead
public class TestSort {
/** Test the Sort.sort method */
public static void testSort() {
String[] input = {"i", "have", "an", "egg"};
String[] expected = {"an", "egg", "have", "i"};
Sort.sort(input);
org.junit.Assert.assertArrayEquals(expected, input);
}
public static void main(String[] args) {
testSort();
}
}
Selection Sort
Back to Sorting: Selection Sort
Selection sorting a list of N items:
Find the smallest item
Move (or swap it) it to the front
Selection sort the remaining N-1 items (without touching front item!)
Let's try implementing this
I'll try to simulate as closely as possible how I think students might approach this problem to show how TDD helps
public class Sort {
/** Sorts strings recursively */
public static void sort(String[] x) {
// Find the smallest item
// Move it to the front
// Selection sort the rest
int smallestIndex = findSmallest(x);
swap(x, 0, smallestIndex);
}
/** Swap item a with b */
public static void swap(String[] x, int a, int b) {
String temp = x[a];
x[a] = x[b];
x[b] = temp;
}
/** Returns the index of the smallest String in x */
public static int findSmallest(String[] x) {
int smallestIndex = 0;
for (int i = 0; i < x.length; i += 1) {
int cmp = x[i].compareTo(x[smallestIndex]);
if (cmp < 0) {
smallestIndex = i;
}
return smallestIndex;
}
}
}
public class TestSort {
/** Test the Sort.sort method */
public static void testSort() {
String[] input = {"i", "have", "an", "egg"};
String[] expected = {"an", "egg", "have", "i"};
Sort.sort(input);
org.junit.Assert.assertArrayEquals(expected, input);
}
/** Test the Sort.findSmallest method */
public static void testFindSmallest() {
String[] input = {"i", "have", "an", "egg"};
int expected = 2;
int actual = Sort.findSmallest(input);
org.junit.Assert.assertEquals(expected, actual);
String[] input2 = {"there", "are", "many", "pigs"};
int expected2 = 1;
int actual = Sort.findSmallest(input2);
org.junit.Assert.assertEquals(expected2, actual2);
}
public static void testSwap() {
String[] input = {"i", "have", "an", "egg"};
int a = 0;
int b = 2;
String[] expected = {"an", "have", "i", "egg"};
Sort.swap(input, input, b);
org.junit.Assert.assertArrayEquals(expected, input);
}
public static void main(String[] args) {
testSwap();
testFindSmallest();
testSort();
}
}
The Evolution of Our Design
Created testSort
Created a sort skeleton
Created testFindSmallest
Created findSmallest
Created testSwap
Created swap
Changed findSmallest
Now we have all the helper methods we need, as well as tests that make us pretty sure that they work
All that's left is to write the sort method itself.
public class Sort {
/** Sorts strings recursively */
public static void sort(String[] x) {
sort(x, 0);
}
/** Sorts x starting at position start */
private static void sort(String[] x, int start) {
if (start == x.length) {
return;
}
int smallestIndex = findSmallest(x, start);
swap(x, start, smallestIndex);
sort(x, start + 1);
}
/** Swap item a with b */
public static void swap(String[] x, int a, int b) {
String temp = x[a];
x[a] = x[b];
x[b] = temp;
}
/** Returns the index of the smallest String in x. Starting at start */
public static int findSmallest(String[] x, int start) {
int smallestIndex = start;
for (int i = start; i < x.length; i += 1) {
int cmp = x[i].compareTo(x[smallestIndex]);
if (cmp < 0) {
smallestIndex = i;
}
return smallestIndex;
}
}
}
public class TestSort {
/** Test the Sort.sort method */
public static void testSort() {
String[] input = {"i", "have", "an", "egg"};
String[] expected = {"an", "egg", "have", "i"};
Sort.sort(input);
org.junit.Assert.assertArrayEquals(expected, input);
}
/** Test the Sort.findSmallest method */
public static void testFindSmallest() {
String[] input = {"i", "have", "an", "egg"};
int expected = 2;
int actual = Sort.findSmallest(input, 0);
org.junit.Assert.assertEquals(expected, actual);
String[] input2 = {"there", "are", "many", "pigs"};
int expected2 = 2;
int actual2 = Sort.findSmallest(input2, 2);
org.junit.Assert.assertEquals(expected2, actual2);
}
/** Test the Sort.swap method */
public static void testSwap() {
String[] input = {"i", "have", "an", "egg"};
int a = 0;
int b = 2;
String[] expected = {"an", "have", "i", "egg"};
Sort.swap(input, input, b);
org.junit.Assert.assertArrayEquals(expected, input);
}
public static void main(String[] args) {
testSwap();
testFindSmallest();
testSort();
}
}
The Evolution of Our Design
Created testSort
Created a sort skeleton
Created testFindSmallest
Created findSmallest
Created testSwap
Created swap
Changed findSmallest
Now we have all the helper methods we need, as well as tests that make us pretty sure that they work
All that's left is to write the sort method itself.
Modified findSmallest
Reflections on the Process
And We're Done!
Often, development is an incremental process that involves lots of task switching and on the fly design modification
Tests provide stability and scaffolding
Provide confidence in basic units and mitigate possibility of breaking them
Help you focus on one task at a time
In larger projects, tests also allow you to safely refactor! Sometimes code gets ugly, necessitating redesign and rewrites
One remaining problem: Sure was annoying to have to constantly edit which tests were running. Let's take care of that
Simpler JUnit Tests
Simple JUnit
New Syntax #1: org.junit.Assert.assertEquals(expected, actual);
Tests that expected equals actual
If not, program terminates with verbose message
JUnit does much more
assertEquals, assertFalse, assertNotNull, etc.
Other more complex behavior to support more sophisticated testing
Better JUnit
The messages output by JUnit are ugly
New Syntax #2
Annotate each test with @org.junit.Test
Change all test methods to non-static
Use a JUnit runner to run all tests and tabulate results
Intellij provides a default runner/renderer. OK to delete main
Rendered output is easier to read, no need to manually invoke tests
Even Better JUnit
It is annoying to type out the name of the library repeatedly
New Syntax #3: To avoid this we'll start every test file with:
import org.junit.Test;
import static org.junit.Assert.*
This will eliminate the need to type org.junit or org.junit.Assert
public class Sort {
/** Sorts strings recursively */
public static void sort(String[] x) {
sort(x, 0);
}
/** Sorts x starting at position start */
private static void sort(String[] x, int start) {
if (start == x.length) {
return;
}
int smallestIndex = findSmallest(x, start);
swap(x, start, smallestIndex);
sort(x, start + 1);
}
/** Swap item a with b */
public static void swap(String[] x, int a, int b) {
String temp = x[a];
x[a] = x[b];
x[b] = temp;
}
/** Returns the index of the smallest String in x. Starting at start */
public static int findSmallest(String[] x, int start) {
int smallestIndex = start;
for (int i = start; i < x.length; i += 1) {
int cmp = x[i].compareTo(x[smallestIndex]);
if (cmp < 0) {
smallestIndex = i;
}
return smallestIndex;
}
}
}
import org.junit.Test;
import static org.junit.Assert.*;
public class TestSort {
/** Test the Sort.sort method */
@org.junit.Test
public void testSort() {
String[] input = {"i", "have", "an", "egg"};
String[] expected = {"an", "egg", "have", "i"};
Sort.sort(input);
assertArrayEquals(expected, input);
}
/** Test the Sort.findSmallest method */
@org.junit.Test
public void testFindSmallest() {
String[] input = {"i", "have", "an", "egg"};
int expected = 2;
int actual = Sort.findSmallest(input, 0);
assertEquals(expected, actual);
String[] input2 = {"there", "are", "many", "pigs"};
int expected2 = 2;
int actual2 = Sort.findSmallest(input2, 2);
assertEquals(expected2, actual2);
}
/** Test the Sort.swap method */
@org.junit.Test
public void testSwap() {
String[] input = {"i", "have", "an", "egg"};
int a = 0;
int b = 2;
String[] expected = {"an", "have", "i", "egg"};
Sort.swap(input, input, b);
assertArrayEquals(expected, input);
}
}
Testing Philosophy
Correctness Tool #1: Autograder
Idea: Magic autograder tells you code works
We use JUnit + jh61b libraries
Why?
Less time wasted on "boring" stuff
Determines your grade
Gamifies correctness
Why not?
Autograders don't exist in real world
Errors may be hard to understand
Slow workflow
No control if grader breaks/misbehaves
Autograder Driven Development (ADD)
The worst way to approach programming:
Read and (mostly) understand the spec
Write entire program
Compile. Fix all compilation errors
Send to autograder. Get many errors
Until correct, repeat randomly
Run autograder
Add print statements to zero in on the bug
Make changes to code to try to fix bug
This workflow is slow and unsafe!
Correctness Tool #2: Unit Tests
Idea: Write tests for every "unit"
JUnit makes this easy!
Why?
Build confidence in basic modules
Decrease debugging time
Clarify the task
Why not?
Building tests take time
May provide false confidence
Hard to test untis that rely on others
e.g. how do you test addFirst?
Test-Driven Development (TDD)
Steps to developing according to TDD:
Identify a new feature
Write a unit test for that feature
Run the test. It should fail
Write code that passes test
Implementation is certifiably good
Optional: Refactor code to make it faster, cleaner, etc.
A Tale of Two Workflows
TDD is an extreme departure from the naive workflow
What's best for you is probably in the middle
Correctness Tool #3: Integration Testing
Idea: Tests cover many units at once
Not JUnit's focus, but JUnit can do this
Why?
Unit testing is not enough to ensure modules interact properly or that system works as expected
Why not?
Can be tedious to do manually
Can be challenging to automate
Testing at highest level of abstraction may miss subtle or rare errors
Parting Thoughts
JUnit makes testing easy
You should write tests
But not too many
Only when they might be useful!
Write tests first when it feels appropriate
Most of the class won't require writing lots of tests (to save you time)
Some people really like TDD. Feel free to use it in 61B.
After adding the insert methods from discussion 3, our AList and SLList classes have the following methods (exact same method signatures for both classes)
Using ALists and SLists: WordUtils.java
Suppose we're writing a library to manipulate lists of words. Might want to write a function that finds the longest word from a list
Suppose we also want to be able to handle ALists. What should we change?
What if we want to be able to handle both?
Method Overloading in Java
Java allows multiple methods with the same name, but with different parameters
This is called method overloading
public static String longest(AList<String> list) {
...
}
public static String longest(SLList<String> list) {
...
}
The Downsides
While overloading works, it is a bad idea in the case of longest
Source code files are unnecessary long
Repeating yourself is aesthetically gross
More code to maintain
Any change made to one, must be made to another
Including bug fixes!
suppose we make another list someday, we'll need yet another function
Hypernyms, Hyponyms, and Interface Inheritance
Hypernyms
Washing your poodle:
Brush your poodle before a bath
Use lukewarm water
Talk to your poodle in a calm voice
Use poodle shampoo
Rinse well
Air-dry
Reward your poodle
Washing your malamute
Brush your malamute before a bath
Use lukewarm water
Talk to your malamute in a calm voice
Use malamute shampoo
Rinse well
Air-dry
Reward your malamute
In natural languages (e.g. English), we have a concept known as "hypernym" to deal with this problem
Dog is a "hypernym" of poodle, malamute, yorkie, etc.
Hypernym and Hyponym
We use the word hyponym for the opposite type of relationship
"dog": Hypernym of "poodle", "malamute"
"poodle": Hyponym of "dog"
Hypernyms and hyponyms compose a hierarchy
A dog "is-a" canine
A canine "is-a" carnivore
Simple Hyponymic Relationships in Java
SLLists and ALists are both clearly some kind of "list"
List is a hypernym of SLList and AList
Expressing this in Java is a two-step process:
Define a reference type for our hypernym (List61B.java)
Specify that SLLists and ALists are hyponyms of that type
Step 1: Defining a List61B.java
We'll use the new keyword interface instead of class to define a List61B
Idea: Interface is a specification of what a List is able to do, not how to do it
public interface List61B<Item> {
public void addLast(Item x);
public Item getLast();
public Item get(int i);
public int size();
public Item removeLast();
public void insert(Item x, int position);
public Item getFirst();
}
Step 2: Implementing the List61B Interface
We'll now:
Use the new implements keyword to tell the Java compiler that SLList and AList are hyponyms of List61B
public class AList<Item> implements List61B<Item> {
...
}
public class SLList<Item> implements List61B<Item> {
...
}
public class WordUtils {
public static String longest(List61B<String> list) {
...
}
}
Overriding vs. Overloading
Method Overriding
If a "subclass" has a method with the exact same signature as in the "superclass", we say the subclass overrides the method
e.g. AList overrides addLast(Item)
Methods with the same name but different signatures are overloaded
public class Math {
public int abs(int a)
public double abs(double a)
}
abs is overloaded
Optional Step 2B: Adding the @Override Annotation
In 61B, we'll always mark every overriding method with the @Override annotation
Example: Mark AList.java's overriding methods with @Override
The only effect of this tag is that the code won't compile if it is not actually an overriding method
Why use @Override?
Main reason: Protects against typos
If you say @Override, but the method isn't actually overriding anything, you'll get a compile error
e.g. public void addLast(Item x)
Reminds programmer that method definition came from somewhere higher up in the inheritance hierarchy
e.g.
public class AList<Item> implements List61B<Item> {
@Override
public Item getItem(int a) {
...
}
}
Interface Inheritance
Interface Inheritance
Specifying the capabilities of a subclass using the implements keyword is known as interface inheritance
Interface: The list of al method signatures
Inheritance: The subclass "inherits" the interface from a superclass
Specifies what the subclass can do, but not how
Subclasses must override all of these methods!
Will fail to compile otherwise
Such relationships can be multi-generational
Figure: Interfaces in white, classes in green
Interface inheritance is a powerful tool for generalizing code
WordUtils.longest works on SLLists, ALists, and even lists that have not yet been invented
Copying the Bits
Two seemingly contradictory facts:
#1: When you set x = y or pass a parameter, you're just copying the bits
#2: A memory box can only hold 64 bit addresses for the appropriate type
Answer: If X is a superclass of , then memory boxes for X may contain Y
An AList is-a List
Therefore List variables can hold ALList addresses
e.g. the following works just fine:
public static void main(String[] args) {
List61B<String> someList = new SLList<>();
someList.addFirst("elk");
}
Implementation Inheritance: Default Methods
Implementation Inheritance
Interface Inheritance:
Subclass inherits signatures, but NOT implementation
Java also allows implementation inheritance
Subclasses can inherit signatures AND implementation
Use the default keyword to specify a method that subclasses should inherit from an interface
Ex. add a default print() to List61B
public interface List61B<Item> {
public void addLast(Item x);
public Item getLast();
public Item get(int i);
public int size();
public Item removeLast();
public void insert(Item x, int position);
public Item getFirst();
/** Prints out the entire List. */
default public void print() {
for (int i = 0; i < size(); i += 1) {
System.out.print(get(i) + ' ');
}
System.out.println();
}
}
Is the print() method efficient?
print() is efficient for AList and inefficient for SLList
See the get method for both classes
Overriding Default Methods
Overriding Default Methods
If you don't like the default method, you can override it
Any call to print() on an SList will use this method instead of default
Use @Override to cate typos like public void pirnt()
public class SLList<Item> {
@Override
public void print() {
for (Node p = sentinel.next; p != null; p = p.next) {
System.out.print(p.item + ' ');
}
}
}
Dynamic Method Selection
Static Type vs. Dynamic Type
Every variable in Java has a "compile-time type", aka "static type"
This is the type specified at declaration. Never changes!
Variables also have a "run-time type", aka "dynamic type"
This is the type specified at instantiation (e.g. when using new)
Equal to the type of the object being pointed at
Dynamic Method Selection For Overridden Methods
Suppose we call a method of an object using a variable with:
compile-time type X
run-time type Y
Then if Y overrides the method, Y's method is used instead
This is known as "dynamic method selection"
More Dynamic Method Selection, Overloading vs. Overriding
The Method Selection Algorithm
Consider the function called foo.bar(x1) where foo has static type TPrime, and x1 has static type T1
At compile time, the compiler verifies that TPrime has a method that can handle T1. It then records the signature of this method
Note: If there are multiple methods that can handle T1, the compiler records the "most specific" one.
At runtime, if foo's dynamic type overrides the recorded signature, use the overridden method. Otherwise, use TPrime's version of the method
Is a vs Has a, Interface vs Implementation Inheritances
Interface vs. Implementation Inheritance
Interface inheritance (aka what):
Allows you to generalize code in a powerful, simple way
Implementation Inheritance (aka how):
Allows code-reuse: Subclasses can rely on superclasses or interfaces
Example: print() implemented in List61B.java
Gives another dimension of control to subclass designers: Can decide whether or not to override default implementations
Important: In both cases, we specify "is-a" relationships, not "has-a"
Good: Dog implements Animal, SLList implements List61B
Bad: Cat implements Claw, Set implements SLList
Dangers of Implementation Inheritance
Particular dangers of implementation inheritance
makes it harder to keep track of where something was actually implemented
Rules for resolving conflicts can be arcane
Ex: What if two interfaces both give conflicting default methods?
Lecture 9: Extends, Casting, Higher Order Functions
9/16/2020
Implementation Inheritance: Extends
The Extends Keyword
When a class is a hyponym of an interface, we use implements
If you want one class to be a hyponym of another class (instead of interface), you use extends
We'd like to build a RotatingSLList that can perform any SLList operation as well as:
rotateRight(): Moves back item to the front
RotatingSLList
Because of extends, RotatingSLList inherits all members of SLList:
All instance and static variables
All methods
All nested classes
Constructors are not inherited
public class RotatingSLList<Item> extends SLList<Item> {
// Rotates list to the right
public void rotateRight() {
Item x = removeLast();
addFirst(x);
}
}
Another Example: VengefulSLList
Suppose we want to build an SLList that:
Remembers all items that have been destroyed by removeLast
Has an additional method printLostItems(), which prints all deleted items
public class VengefulSLList<Item> extends SLList<Item> {
SLList<Item> deletedItems;
public VengefulSLList() {
super(); // Optional line
deletedItems = new SLList<Item>();
}
@Override
public Item removeLast() {
Item x = super.removeLast(); // Calls Superclass's version of removeLast()
deletedItems.addLast(x);
return x;
}
// Prints deleted items
public void printLostItems() {
deletedItems.print();
}
}
Constructor Behavior is Slightly Weird
Constructors are not inherited. However, the rules of Java say that all constructors must start with a call to one of the super class's constructor
Idea: If every VengefulSLList is-an SLList, every VengefulSLList must be set up like an SLList
If you didn't call SLList constructor, sentinel would be null. Very bad.
You can explicitly call the constructor with the keyword super (no dot)
If you do not explicitly call the constructor, Java will automatically do so for you
Calling Other Constructors
If you want to use a super constructor other than the no-argument constructor, can give parameters to super
public class VengefulSLList<Item> extends SLList<Item> {
SLList<Item> deletedItems;
public VengefulSLList() {
super(); // Optional line
deletedItems = new SLList<Item>();
}
public VengefulSLList(Item x) {
super(x); // NOT OPTIONAL! (calls no-argument constructor otherwise)
deletedItems = new SLList<Item>();
}
}
The Object Class
As it happens, every type in Java is a descendant of the Object class
VengefulSLList extends SLList
SLList extends Object (implicitly)
Interfaces do not extend the object class
Is-a vs. Has-A
Important Note: extends should only be used for is-a (hypernymic) relationships
Common mistake is to use it for "has-a" relationships
Encapsulation
Complexity: The Enemy
When building large programs, our enemy is complexity
Some tools for managing complexity
Hierarchical abstraction
Create layers of abstraction, with clear abstraction barriers
"Design for change" (D. Parnas)
Organize program around objects
Let objects decide how things are done
Hide information others don't need
Managing complexity supremely important for large projects (e.g. project 2)
Modules and Encapsulation
Module: A set of methods that work together as a whole to perform some task or set of related tasks
A module is said to be encapsulated if its implementation is completely hidden, and it can be accessed only through a documented interface
Instance variable private. Methods like resize private
A Cautionary Tale
Interesting questions from project 1B
How can we check the length of StudentArrayDeque?
Private access in given classes
Can we assume these things about StudentArrayDeque?
Abstraction Barriers
As the user of an ArrayDeque, you cannot observe its internals
Even when writing tests, you don't (usually) want to peer inside
Java is a great language for enforcing abstraction barriers with syntax
Implementation Inheritance Breaks Encapsulation
What would vd.barkMany(3) output? (vd is a VerboseDog)
An infinite loop!
public void bark() {
barkMany(1);
}
public void barkMany(int N) {
for (int i = 0; i < N; i += 1) {
System.out.println("bark");
}
}
@Override
public void barkMany(int N) {
System.out.println("As a dog, I say: ") {
for (int i = 0; i < N; i += 1) {
bark(); // calls inherited bark method
}
}
}
Type Checking and Casting
Reminder: Dynamic Method Selection
If overridden, decide which method to call based on run-time type (dynamic type) of variable
Compile-Time Type Checking
Compiler allows method calls based on compile-time type (static type) of variable
Compiler also allows assignments based on compile-time types
Compiler plays it as safe as possible with type checking
Compile-Time Types and Expressions
Expressions have compile-time types
An expression using the new keyword has the specified compile-time type
SLList<Integer> s1 = new VengefulSLList<Integer>();
Compile-time type of right hand side (RHS) expression is VengefulSLList
A VengefulSLList is-an SLList, so assignment is allowed
VengefulSLList<Integer> vs1 = new SLList<Integer>();
Compile-time type of RHS expression is SLList
An SLList is not necessarily a VengefulSLList, so compilation error results
Compile-Type Types and Expressions
Expressions have compile-time types
Method class have compile-time type equal to their declared type
public static Dog maxDog(Dog d1, Dog d2) {...}
Any call to maxDog will have compile-time type Dog!
Example:
Poodle frank = new Poodle("Frank", 5);
Poodle frankJr = new Poodle("Frank Jr." 15);
dog largerDog = maxDog(frank, frankJr);
Poodle largerPoodle = maxDog(frank, frankJr); // Compilation Error!
// RHS has compile-time type Dog
Casting
Java has a special syntax for forcing the compile-time type of any expression
Put desired type in parenthesis before expression
Examples:
Compile-time type Dog: maxDog(frank, frankJr);
Compile-time type Poodle: (Poodle) maxDog(frank, frankJr);
Think of it as a way to trick the compiler
Poodle frank = new Poodle("Frank", 5);
Poodle frankJr = new Poodle("Frank Jr." 15);
dog largerDog = maxDog(frank, frankJr);
Poodle largerPoodle = (Poodle) maxDog(frank, frankJr); // Compilation OK!
// RHS has compile-time type Poodle
Casting is a powerful but dangerous tool
Tells Java to treat an expression as having a different compile-time type
Effectively tells the compiler to ignore its type checking duties
Poodle frank = new Poodle("Frank", 5);
Malamute frankSr = new Malamute("Frank Sr.", 100);
Poodle largerPoodle = (Poodle) maxDog(frank, frankSr);
If we run the code above, we get a ClassCastException at runtime
Higher Order Functions (A First Look)
Higher Order Functions
Higher Order Function: A function that treats another function as data
Fundamental issue: Memory boxes (variables) cannot contain pointers to functions
Can use an interface instead. Let's try it out
// Represents a function that takes in an integer, and returns an integer
public interface IntUnaryFunction {
int apply(int x);
}
public class TenX implements IntUnaryFunction {
/** Returns ten times the argument */
public int apply(int x) {
return 10 * x;
}
}
// Demonstrates higher order functions in Java
public class HofDemo {
public static int doTwice(IntUnaryFunction f, int x) {
return f.apply(f.apply(x));
}
public static void main(String[] args) {
IntUnaryFunction tenX = new TenX();
System.out.println(doTwice(tenX, 2));
}
}
Very verbose
Implementation Inheritance Cheatsheet
VengefulSLList extends SLList means a VengefulSLList is-an SLList. Inherits all members!
Variables, methods, nested classes
Not constructors
Subclass constructor must invoke superclass constructor first
Use super to invoke overridden superclass methods and constructors
Invocation of overridden methods follows two simple rules:
Compiler plays it safe and only lets us do things allowed by static type
For overridden methods the actual method invoked is based on dynamic type of invoking expressions
Does not apply to overloaded methods!
Can use casting to overrule compiler type checking.
You may find questions on old 61B exams, worksheets, etc. that consider:
What if a subclass has variables with the same name as a superclass?
What if subclass has a static method with the same signature as a superclass method?
For static methods, we do not use the term overriding for this
These two practices above are called "hiding"
Bad style
There is no good reason to ever do this
The rules for resolving the conflict are a bit confusing to learn
Will not be taught or tested in 61B
Subtype Polymorphism
Subtype Polymorphism
The biggest idea of the last couple of lectures: subtype polymorphism
Polymorphism: "providing a single interface to entities of different types"
Consider a variable deque of static type Deque:
When you call deque.addFirst(), the actual behavior is based on the dynamic type
Java automatically selects the right behavior using what is sometimes called "dynamic method selection"
Subtype Polymorphism vs. Explicit Higher Order Functions
Suppose we want to write a program that prints a string representation of the larger of two objects
Explicit HoF Approach
def print_larger(x, y, compare, stringify):
if compare(x, y):
return stringify(x)
return stringify(x)
Subtype Polymorphism Approach
def print_larger(x, y):
if x.largerThan(y):
return x.str()
return y.str()
DIY Comparison
shoutkey.com/TBA
Suppose we want to write a function max() that returns the max of any array, regardless of type
Writing a General Max Function: The Fundamental Problem
Objects cannot be compared to objects with >
One (bad) way to fix this: Write a max method in the Dog class
What is the disadvantage of this?
Given up dream of one true max function
You will need a max function for each new class
Redundant code
How could we fix our Maximizer class using inheritance / HoFs?
Solution
Create an interface that guarantees a comparison method
Have Dog implement this interface
Write Maximizer class in terms of this interface
public static OurComparable max(OurComparable[] items) {...}
public interface OurComparable {
/** Return negative number if this is less than o
* Return 0 if this is equal to o
* Return positive number if this if greater than o
*/
public int compareTo(Object obj);
}
public class Dog implements OurComparable {
private String name;
private int size;
public Dog(String n, int s) {
name = n;
size = s;
}
public void bark() {
System.out.println(name + " says: bark");
}
// Returns negative number if this dog is less than the dog pointed by o, and so forth
public int compareTo(Object o) {
Dog otherDog = (Dog) o;
return this.size - otherDog.size;
}
}
public class Maximizer {
public static OurComparable max(OurComparable[] items) {
int maxDex = 0;
for (int i = 0; i < items.length; i += 1) {
int cmp = items[i].compareTo(items[maxDex])
if (cmp > 0) {
maxDex = i;
}
}
return items[maxDex];
}
}
The OurComparable Interface
Specification, returns:
Negative number if this is less than obj
0 if this is equal to object
Positive number if this is greater than obj
General Maximization Function Through Inheritance
Benefits of this approach
No need for array maximization code in every custom type (i.e. no Dog.maxDog(Dog[]) function required)
Code that operates on multiple types (mostly) gracefully
Comparables
The Issues with OurComparable
Two issues:
Awkward casting to/from Objects
We made it up
No existing classes implement OurComparable (e.g. string, etc)
No existing classes use OurComparable (e.g. no built-in max function that uses OurComparable)
The industrial strength approach: Use the built-in Comparable interface
Already defined nad used by tons of libraries. Uses generics.
public class Dog implements Comparable<Dog> {
...
// Returns negative number if this dog is less than the dog pointed by o, and so forth
public int compareTo(Dog otherDog) {
return this.size - otherDog.size;
}
}
public class Maximizer {
public static Comparable max(Comparable[] items) {
int maxDex = 0;
for (int i = 0; i < items.length; i += 1) {
int cmp = items[i].compareTo(items[maxDex])
if (cmp > 0) {
maxDex = i;
}
}
return items[maxDex];
}
}
Comparable Advantages
Lots of built in classes implement Comparable (e.g. String)
Lots of libraries use the Comparable interface (e.g. Arrays.sort)
Avoids need for casts
Comparators
Natural Order
The term "Natural Order" is used to refer to the ordering implied by a Comparable's compareTo method
Example: Dog objects (as we've defined them) have a natural order given by their size
May wish to order objects in a different way
Example: by name
Additional Orders in Java
The standard Java approach: Create sizeComparator and nameComparator classes that implement the Comparator interface
Requires methods that also take Comparator arguments
import java.util.Comparator;
public class Dog implements OurComparable {
...
// Returns negative number if this dog is less than the dog pointed by o, and so forth
public int compareTo(Object o) {
Dog otherDog = (Dog) o;
return this.size - otherDog.size;
}
private static class NameComparator implements Comparator<Dog> {
public int compare(Dog a, Dog b) {
return a.name.compareTo(b.name);
}
}
public static Comparator<Dog> getNameComparator() {
return new NameComparator();
}
}
import java.util.Comparator;
public class DogLauncher {
public static void main(String[] args) {
...
Comparator<Dog> nc = new Dog.getNameComparator();
if (nc.compare(d1, d3) > 0) {
d1.bark();
} else {
d2.bark();
}
}
}
Comparable and Comparator Summary
Interfaces provide us with the ability to make callbacks
Sometimes a function needs the help of another function that might not have been written yet
Example: max needs compareTo
The helping function is sometimes called a "callback"
Some languages handle this using explicit function passing
In Java, we do this by wrapping up the needed function in an interface (e.g. Arrays.sort needs compare which lives inside the comparator interface)
Arrays.sort "call back" whenever it needs a comparison
Similar to giving your number to someone if they need information
In lecture, we've built two types of lists: ALists and SLLists
Similar to Python lists
List61B<Integer> L = new AList<>();
L.addLast(5);
L.addLast(10);
L.addLast(15);
L.print();
We built a list from scratch, but Java provides a built-in List interface and several implementations, eg ArrayList
java.util.List<Integer> L = new java.util.ArrayList<>();
L.add(5);
L.add(10);
L.add(15);
System.out.println(L);
Lists in Real Java Code
By including "import java.util.List" and "import java.util.ArrayList", we can make our code more compact
import java.util.List;
import java.util.ArrayList;
List<Integer> L = new ArrayList<>();
Sets in Java and Python
Another data structure is the set
Stores a set of values with no duplicates. Has no sense of order.
Set<String> S = new HashSet<>();
S.add("Tokyo");
S.add("Beijing");
S.add("Lagos");
S.add("Sao Paulo");
Sysetme.out.println(S.contains("Tokyo"));
ArraySet
Today we're going to write our own set called ArraySet
Goals
Goal 1: Create a class ArraySet with the following methods:
add(value): Add the value to the set if it is not already present
contains(value): Checks to see if ArraySet contains the key
size(): Returns the size of the array
ArraySet (Basic Implementation)
public class ArraySet<T> {
private T[] items;
private int size;
public ArraySet() {
items = (T[]) new Object[100];
size = 0;
}
public boolean contains(T x) {
for (int i = 0; i < size; i += 1) {
if (e.equals(items[i])) {
return true;
}
}
return false;
}
public void add(T x) {
if (contains(x)) {
return;
}
items[size] = x;
size += 1;
}
public int size() {
return size;
}
}
Exceptions
Exceptions
Basic idea:
When something goes really wrong, break the normal flow of control
So far, we've only seen implicit exceptions
public class ArraySet<T> {
...
public void add(T x) {
if (x == null) {
throw new IllegalArgumentException("You can't add null to an ArraySet");
}
if (contains(x)) {
return;
}
items[size] = x;
size += 1;
}
...
}
Explicit Exceptions
We can also throw our own exceptions using the throw keyword
Can provide more informative message to a user
Can provide more information to code that "catches" the exception
Arguably this is a bad exception
Our code now crashes when someone tries to add a null
Other fixes:
Ignore nulls
Fix contains so it doesn't crash when it tries to add null
public boolean contains(T x) {
if (items[i] == null) {
if (x == null) {
return true;
}
}
if (e.equals(items[i])) {
return true;
}
}
Iteration
The Enhanced For Loop
Java allows us to iterate through Lists and Sets using a convenient shorthand syntax sometimes called the "foreach" or "enhanced for" loop
Doesn't work with our ArraySet
for (int i : javaset) {
System.out.println(i);
}
How Iteration Really Works
An alternate, uglier way to iterate through a List is to use the iterator() method
ArraySet<Integer> = new ArraySet<>();
Iterator<Integer> seer = aset.iterator();
while (seer.hasNext()) {
int i = seer.next();
System.out.println(i);
}
To make this work, the Set interface needs to have an iterator() method and the iterator interface needs to have next/hasNext() methods
Support Ugly Iteration in ArraySets
To support ugly iteration:
Add an iterator() method to ArraySet that returns an Iterator<T>
The Iterator<T> that we return should have a useful hasNext() and next() method
public class ArraySet<T> implements Iterable<T> {
...
public Iterator<T> iterator() {
return new ArraySetIterator();
}
private class ArraySetIterator implements Iterator<T> {
private int wizPos;
public ArraySetIterator() {
wizPos = 0;
}
public boolean hasNext() {
return wizPos < size;
}
public T next() {
T returnItem = items[wizPos];
wizPos += 1;
return returnItem;
}
}
}
The Enhanced For Loop
The problem: Java isn't smart enough to realize that our ArraySet has an iterator() method
Luckily there's an interface for that
To support the enhanced for loop, we need to make ArraySet implement the Iterable interface
public interface Iterable<T> {
Iterator<T> iterator();
}
public class ArraySet<T> implements Iterable<T> {
...
public Iterator<T> iterator() {
return new ArraySetIterator();
}
private class ArraySetIterator implements Iterator<T> {
private int wizPos;
public ArraySetIterator() {
wizPos = 0;
}
public boolean hasNext() {
return wizPos < size;
}
public T next() {
T returnItem = items[wizPos];
wizPos += 1;
return returnItem;
}
}
}
The Iterable Interface
By the way, this is how Set works as well
Set implements Collection which implements Iterable
Iteration Summary
To support the enhanced for loop:
Add an iterator() method to your class that returns an Iterator<T>
The Iterator<T> returned should have a useful hasNext() and next() method
Add implements Iterable<T> to the line defining your class
Object Methods: Equals and toString()
Objects
All classes are hyponyms of Object
toString()
The toString() method provides a string representation of an object
System.out.println(Object x) calls x.toString()
println calls String.valueOf which calls toString
The implementation of toString() in Object is the name of the class, then an @ sign, then the memory location of the object
ArraySet toString
One approach is shown below
Warning: This code is slow. Intuition: Adding even a single character to a string creates an entirely new string. Will discuss why at the end of the course.
public class ArraySet<T> implements Iterable<T> {
...
@Override
public String toString() {
String returnString = "{";
for (int i = 0; i < size - 1; i += 1) {
returnString += item.toString();
return String += ", ";
}
returnString += items[size - 1];
returnString += "}";
return returnString;
}
}
ArrayMap toString
Intuition: Append operation for a StringBuilder is fast
public class ArraySet<T> implements Iterable<T> {
...
@Override
public String toString() {
StringBuilder returnSB = new StringBuilder("{");
for (int i = 0; i < size - 1; i += 1) {
returnSB.append(items[i].toString());
returnSB.append(", ");
}
returnS.append(items[size - 1]);
returnString.append("}");
return returnSB.toString();
}
}
Equals vs. ==
As mentioned before, == and .equals() behave differently
== compares the bits. For references, == means "referencing the same object"
An engineer will do for a dime what any fool will do for a dollar
Execution cost (from today to the end of the course)
How much time does your program take to execute?
How much memory does your program require?
Example of Algorithm Cost
Objective: Determine if a sorted array contains any duplicates
Given sorted array A, are there indices i and j where A[i] = A[j]
Silly algorithm: Consider every possible pair, returning true if any match
Better algorithm:
For each number A[i], look at A[i+1], and return true the first time you see a match. If you run out of items, return false.
Characterization 1 Clock Time
How Do I Runtime Characterization?
Our goal is to somehow characterize the runtimes of the different functions/algorithms
Characterization should be simple and mathematically rigorous
Characterization should demonstrate superiority of more efficient algorithms
Techniques for Measuring Computational Cost
Technique 1: Measure execution time in seconds using a client program
Tools:
Physical stopwatch
Good: Easy to measure, meaning is obvious
Bad: May require large amounts of computation time. Result varies with machine, compiler, input data, etc.
Techniques for Measuring Computational Cost
Technique 2A: Count possible operations for an array of size N = 10000
Good: Machine independent. Input dependence captured in model.
Bad: Tedious to compute. Array size was arbitrary. Doesn't tell you actual time.
Technique 2B: Count possible operations in terms of input array size N
Good: Machine independent. Input dependence captured in model. Tells you how the algorithm scales
Bad: Even more tedious to compute. Doesn't tell you actual time.
Why Scaling Matters
Comparing Algorithms
Good algorithms scale better in the worst case
In the case of our two algorithms, parabolas (N^2) grow faster than lines (N)
Asymptotic Behavior
In most cases, we care only about asymptotic behavior, i.e. what happens for very large N
Simulation of billions of interacting particles
Social network with billions of users
Logging of billions of transactions
Encoding of billions of bytes of video data
Algorithms which scale well (e.g. look like lines) have better asymptotic runtime behavior than algorithms that scale relatively poorly (e.g. look like parabolas)
Parabolas vs. Lines
Suppose we have two algorithms that zerpify a collection of N items
zerp1 takes 2N^2 operations
zerp2 takes 500N operations
For small N, zerp1 might be faster, but as dataset size grows, the parabolic algorithm is going to fall farther and farther behind (in time it takes to complete)
Scaling Across Many Domains
We'll informally refer to the "shape" of a runtime function as its order of growth
Effect is dramatic! Often determines whether a problem can be solved at all.
Worst Case Orders of Growth
Intuitive Simplification 1: Consider Only the Worst Case
Simplification 1: Consider only the worst case
Justification: When comparing algorithms, we often care only about the worst case [but we will see exceptions in this course]
Intuitive Simplification 2: Restrict Attention to One Operation
Simplification 2: Pick some representative operation to act as a proxy for the overall runtime
We call our choice the "cost model"
Intuitive Simplification 3: Eliminate low order terms
Why? It has no real meaning. We already threw away information when we chose a single proxy operation
Simplification Summary
Simplifications:
Consider only the worst case
Pick a representative operation (aka the cost model)
Ignore lower order terms
Ignore multiplicative constants
We only care about the order of growth of the runtime
Simplified Analysis
Simplified Analysis Process
Rather than building the entire table, we can instead:
Choose a representative operation to count (aka cost model)
Figure out the order of growth for the count of the representative operation by either:
Making an exact count, then discarding the unnecessary pieces
Using intuition and inspection to determine order of growth
Analysis of Nested For Loops (Based on Exact Count)
int N = A.length;
for (int i = 0; i < N; i += 1) {
for (int j = i + 1; j < N; j += 1) {
if (A[9] == A[j]) {
return true;
}
}
}
return false
Find the order of growth of the worst case runtime of dup1
Worst case number of == operations
C = 1 + 2 + ... + (N-2) + (N-1) = N(N-1)/2
Worst case order of growth for == is N^2
Worst case order of growth of runtime: N^2
AnLysis of Nested For Loops (Simpler Geometric Argument)
Find order of growth of the worst case runtime of dup1
Worst case number of == operations:
Given by area of right triangle of side length N-1
Order of growth of area is N^2
Operation == has worst case order of growth N^2
Worst case order of growth of runtime: N^2
Formalizing Order of Growth
Given a function Q(N), we can apply our last two simplifications to yield the order of growth of Q(N)
Let's finish this lecture by moving to a more formal notation called Big-Theta
Big-Theta: Formal Definition
Big-Theta and Runtime AnLysis
Using Big-Theta doesn't change anything about runtime analysis
The only difference is that we use the Theta symbol
Big O Notation
Big O
Whereas Big Theta can be thought of like "equals", Big O can be thought of as "less than or equal"
Big Theta vs. Big O
Big Theta:
Order of growth is f(N)
Big O:
Order of growth is less than or equal to f(N)
Summary
Given a code snippet, we can express its runtime as a function R(N) where N is some property of the input of the function (often the size of the input)
Rather than finding R(N) exactly, we instead usually only care about the order of growth of R(N)
One approach (not universal)
Choose a representative operation, and let C(N) be the count of how many times that operation occurs as a function of N
Determine order of growth f(N) for C(N)
Often (but not always) we consider the worst case count
If an operation takes constant time, then R(N) corresponds to C(N)
Can use O as an alternative for Big Theta. O is used for upper bounds.
Summary From Discussion
Aymptotics
Asymptotics allow us to evaluate the performance of our programs using math. We ignore all constants and only care about the value with reference to the input (usually defined as N)
Big O - The upper found in terms of the input (essentially, assume every conditional statement evaluates to the worst case)
Big Omega - The lower bound in terms of the input (essentially, assume every conditional statement evaluates to the best case)
Big Theta - The tightest bound, which only exists when the tightest upper bound and the tightest lower bound converge to the same value
Meta-goals of the Coming Lectures: Data Structure Refinement
Today: Deriving the "Disjoint Sets" data structure for solving the "Dynamic Connectivity" problem. We will see:
How a data structure design can evolve from basic to sophisticated
How our choice of underlying abstraction can affect asymptotic runtime and code complexity
The Disjoint Sets Data Structure
The Disjoint Sets data structure has two operations:
connect(x, y): Connects x and y
isConnected(x, y): Returns true if x and y are connected. Connections can be transitive, i.e. they don't need to be direct
Useful for many purposes
Percolation theory:
Computational chemistry
Implementation of other algorithms
Kruskal's algorithm
Disjoint Sets on Integers
To keep things simple, we're going to:
Force all items to be integers instead of arbitrary data
Declare the number of items in advance, everything is disconnected at start
The Disjoint Sets Interface
public interface DisjointSets {
/** Connects two items P and Q */
void connect(int p, int q);
/** Checks to see if two items are connected */
boolean isConnected(int p, int q);
}
Goal: Design an efficient DisjointSets implementation
Number of elements N can be huge
Number of method calls M can be huge
Calls to methods may be interspersed (e.g. can't assume it's only connect operations followed by only isConnected operations)
The Naive Approach
Naive approach:
Connect two things: Record every single connecting line in some data structure
Checking connectedness: Do some sort of iteration over the lines to see if one thing can be reached from the other
A Better Approach: Connected Components
Rather than manually writing out every single connecting line, only record the sets that each item belongs to
For each item, its connected component is the set of all items that are connected to that item
Better approach: Model connectedness in terms of sets
How things are connected isn't something we need to know
Only need to keep track of which connected component each item belongs to
Quick Find
Performance Summary
ListOfSetsDS
Constructor: Theta(N)
Connect: Theta(N)
isConnected: O(N)
ListofSetsDS is complicated and slow
Operations are linear when number of connections are small
Have to iterate over all sets
Important point: By deciding to use List of Sets, we have doomed ourselves to complexity and bad performance
My Approach: Just use a list of integers
Idea #2: List of integers where ith entry gives set number (aka "id") of item i
connect(p, q): Change entries that equal id[p] and id[q]
QuickFindDS
Constructor: Theta(N)
Connect: Theta(N)
isConnected: Theta(1)
Quick Union
Improving the Connect Operation
Next approach (Quick Union): We will still represent everything as connected components, and we will still represent connected components as a list of integers. However, values will be chosen so that connect is fast
How could we change our set representation so that combining two sets into their union requires changing one value?
Idea: Assign each item a parents (instead of an id). Results in a tree-like shape
An innocuous sounding, seemingly arbitrary solution
Ex: connect(5, 2)
Find root(5)
Find root(2)
Set root(5)'s value equal to root(2)
Set Union Using Rooted-Tree Representation
What are some potential performance issues with this approach
Tree can get too tall! root(x) becomes expensive
For N items, this means a worst case runtime of Theta(N)
QuickUnionDS
Constructor: Theta(N)
Connect: O(N)
isConnected: O(N)
QuickUnion defect: Trees can get tall. Results in potentially even worse performance than QuickFind if tree is imbalanced
Observation: Things would be fine if we just kept our tree balanced
Weighted Quick Union
Weighted Quick Union
Modify quick-union to avoid tall trees
Track tree size (number of elements)
New rule: Always link root of smaller tree to larger tree
Note: this rule is based on weight, not height
Implementing WeightedQuickUnion
Minimal changes needed
Use parent[] array as before
isConnected(int p, int q) requires no changes
connect(int p, int q) needs to somehow keep track of sizes
Two common approaches:
Use values other than -1 in parent array for root nodes to track size
Create a separate size array
Weighted Quick Union Performance
Consider the worst case where the tree height grows as fast as possible
The height increases logarithmically with respect to the number of elements
Worst case tree height is Theta(log N)
Performance Summary
WeightedQuickUnionDS
Constructor: Theta(N)
Connect: O(log N)
isConnected(log N)
QuickUnion's runtimes are O(H), and WeightedQuickUnionDS height is given by H = O(log N). THerefore connect and isConnected are both O(log N)
By tweaking QuickUnionDS we've achieved logarithmic time performance
Why Weights Instead of Heights?
We used the number of items in a tree to decide upon the root
Why not use the height of the tree?
Worst case performance for HeightedQuickUnionDS is asymptotically the same! Both are Theta(log N)
Resulting code is complicated with no performance gain
Path Compression (CS 170 Spoiler) (Can we do better?)
What We've Achieved
Performing M operations on a DisjointSet object with N elements:
For our naive implementation, runtime is O(MN)
For our best implementation, runtime is O(N + M log N)
Key point: Good data structure unlocks solutions to problems that could otherwise not be solved!
Good enough for all practical uses, but could we theoretically do better?
CS 170 Spoiler: Path Compression: A Clever Idea
Below is the topology of the worst case if we use WeightedQuickUnion
Clever Idea: When we do isConnected(15, 10), tie all nodes seen to the root
Additional cost is insignificant (same order of growth)
Path compression results in a union/connected operations that are very very close to amortized constant time
M operations on N nodes is O(N + M lg* N) - you will see this in CS 170
lg* is less than 5 for any realistic input
A tighter bound: O(N + M \alpha(N)), where \alpha is the inverse Ackermann function
The inverse Ackermann function is less than 5 for all practical inputs!
A Summary of Our Iterative Design Process
And we're done! The end result of our iterative design process is the standard way disjoint sets are implemented today - quick union and path compression
The ideas that made our implementation efficient:
Represent sets as connected components (don't track individual connections)
ListofSetsDS: Store connected components as a List of Sets (slow, complicated)
QuickFindDS: Store connected components as set ids
QuickUnionDS: Store connected components as parent ids
WeightedQuickUnionDS: Also track the size of each set, and use size to decide on a new tree root
WeightedQuickUnionWithPathCompressionDS: On calls to connect and isConnected, set parent id to the root for all items seen
Summary From Discussion
Disjoint Sets
QuickFind uses an array of integers to track which set each element belongs to
QuickUnion stores the parent of each node rather than the set to which it belongs sto and merges sets by setting the parent of one root to the other
WeightedQuickUnion does the same as QuickUnion except it decides which set is merged into which by size, reducing the likelihood of large trees
WeightedQuickUnion with Path Compression sets the parent of each node to the set's root whenever find() is called on it
Count number of calls to f3, by a "recurrence relation"
C(1) = 1
C(N) = 2C(N-1) + 1
More technical to solve. Won't do this in our course
Binary Search
Binary Search Intuitive
Finding a key in a sorted array
Compare key against middle entry
Too small, go left
Too big, go right
Equal, found
The runtime of binary search is Theta(log_2(N))
Why? Problem size halves over and over until it gets down to 1
Binary Search Exact Count
Find worst case runtime for binary search
What is C(6), number of total calls for N = 6?
3
Three total calls, where N = 6, N = 3, and N = 1
C(N) = floor(log_2(N)) + 1
Since compares take constant time, R(N) = Theta(floor(log_2(N)))
This f(N) is way too complicated. Let's simplify.
Three useful properties:
floor(f(N)) = Theta(f(N))
The floor of f has the same order of growth as f
ceiling(f(N)) = Theta(f(N))
The ceiling of f has the same order of growth as f
log_p(N) = Theta(log_q(N))
logarithm base does not affect order of growth
Hence, floor(log_2(N)) = Theta(log N)
Since each call takes constant time, R(N) = Theta(log N)
Binary Search (using Recurrence Relations)
C(0) = 0
C(1) = 1
C(N) = 1 + C((N-1)/2)
Log Time is Really Terribly Fast
In practice, logarithm time algorithms have almost constant runtimes
Even for incredibly huge datasets, practically equivalent to constant time
Merge Sort
Selection Sort: A Prelude to Mergesort
Earlier in class we discussed a sort called selection sort:
Find the smallest unfixed item, move it to the front, and "fix" it
Sort the remaining unfixed items using selection sort
Runtime of selection sort is Theta(N^2)
Look at all N unfixed items to find smallest
The look at N-1 remaining unfixed
...
Look at last two unfixed items
Done, sum 2+3+4+5+...+N = Theta(N^2)
Given that runtime is quadratic, for N = 64, we might say the runtime for selection sort is 2048 arbitrary units of time (AU)
The Merge Operation
Given two sorted arrays, the merge operation combines them into a single sorted array by successively copying the smallest item from the two arrays into a target array
What is the time complexity of the merge operation?
Theta(N)
Why? Use array writes as cost model, merge does exactly N writes
Using Merge to Speed Up the Sorting Process
Merging can give us an improvement over vanilla selection sort:
Selection sort the left half: Theta(N^2)
Selection sort the right half: Theta(N^2)
Merge the results: Theta(N)
N = 64: ~1088 AU
Merge: ~64 AU
Selection sort: ~2*512 = ~1024 AU
Still Theta(N^2), but faster since N + 2*(N/2)^2 < N^2
1088 vs 2048 AU for N=64
Two Merge Layers
Can do even better by adding a second layer of merges
Two layers of merges: ~640 AU
Example 5: Mergesort
Mergesort does merges all the way down (no selection sort):
If array is of size 1, return
Mergesort the left half
Mergesort the right half
Merge the results
Total runtime to merge all the way down: ~384 AU
Top layer: ~64 = 64 AU
Second layer: ~32 * 2 = 64 AU
Third layer: ~16 * 4 = 64 AU
Overall runtime in AU is ~64k, where k is the number of layers
k = log_2(64) = 6, so ~384 total AU
Mergesort Order of Growth
Mergesort has worst case runtime = Theta(N log N)
Every level takes ~N AU
Top level takes ~N AU
Top level takes ~N/2 + N/2 = ~N
etc. etc.
Thus, total runtime is ~Nk, where k is the number of levels
Note that k = log_2(N)
Overall runtime is Theta(N log N)
Linear vs. Linearithmic (N log N) vs Quadratic
N log N is basically as good as N, and is vastly better than N^2
For N = 1000000, the log N is only 20
Summary
Theoretical analysis of algorithm performance requires careful thought
There are no magic shortcuts for analyzing code
In our course, it's OK to do exact counting or intuitive analysis
Know how to sum 1 + 2 + 3 + ... + N and 1 + 2 + 3 + ... + N
We won't be writing mathematical proofs in this class
Many runtime problems you'll do in this class resemble one of the five problems from today. See textbook, study guide, and discussion for more practice
This topic has one of the highest skill ceilings of all topics in the course
Different solutions to the same problem may have different runtimes
N^2 vs. N log N is an enormous difference
Going from N log N to N is nice, but not a radical change
We implemented a set based on unordered arrays. For the order linked list set implementation, name an operation that takes worst case linear time, i.e. Theta(N)
Both contains and add will take linear time
Optimization: Extra Links
Fundamental Problem: Slow search, even though it's in order
Add (random) express lanes. Skip List (won't discuss in 61B)
Optimization: Change the Entry Point
Fundamental Problem: Slow search, even though it's in order
Move pointer to middle and flip left links. Halved search time!
How do we do even better?
BST Definitions
Tree
A tree consists of
A set of nodes
A set of edges that connect those nodes
Constraint: There is exactly one path between any two nodes
Rooted Trees and Rooted Binary Trees
In a rooted tree, we call one node the root
Every node N except the root has exactly one parent, defined as the first node on the path from N to the root
A node with no child is called a leaf
In a rooted binary tree, every node has either 0, 1, or 2 children (subtrees)
Binary Search Trees
A binary search tree is a rooted binary tree with the BST property
BST Property. For every node X in the tree
Every key in the left subtree is less than X's key
Every key in the right subtree is greater than X's tree
Ordering must be complete, transitive, and antisymmetric. Given keys p and q:
Exactly one of p < q and q < p are true
p < q and q < r implies p < r
One consequence of these rules: No duplicate keys allowed!
Keep things simple. Most real world implementations follow this rule
BST Operations: Search
Finding a searchKey in a BST
If searchKey returns T.key, return
If searchKey < T.key, search T.left
If searchKey > T.key, search T.right
static BST find(BST T, key sk) {
if (T == null)
return null;
if (sk.equals(T.key))
return T;
else if (sk < T.key)
return find(T.left, sk);
else
return find(T.right, sk);
}
What is the runtime to complete a search on a "bushy" BST in the worst case, where N is the number of nodes?
Answer is Theta(log N)
Height of the tree is ~log_2(N)
BSTs
Bushy BSTs are extremely fast
Much computation is dedicated towards finding things in response to queries
It's a good thing that we can do such queries almost for free
BST Operations: Insert
Inserting a new key into a BST
Search for key
If found, do nothing
If not found
Create a new node
Set appropriate link
static BST insert(BST T, Key ik) {
if (T == null)
return new BST(ik);
if (ik < T.key)
T.left = insert(T.left, ik);
else if (ik > T.key)
T.right = insert(T.right, ik);
return T;
}
BST Operation: Delete
Deleting from a BST
3 Cases:
Deletion key has no children
Deletion key has one child
Deletion key has two children
Case 1: Deleting from a BST: Key with no Children
Deletion key has no children
Just sever hte parent's link
Garbage collected
Case 2: Deleting from a BST: Key with one Child
Goal: Maintain BST property
Key's child definitely larger than parent
Safe to just move that child into key's spot
Thus: Move key's parent's pointer to key's child
Key will be garbage collected (along with its instance variables)
Case 3: Deleting from a BST: Deletion with two Children
Goal:
Find a new root node
Must be > than everything in left subtree
Must be < than everything in right subtree
Choose either predecessor or successor
Delete predecessor (the largest key smaller than the removed key) or successor (the smallest key larger than the removed key), and stick new copy in the root position
This deletion guaranteed to be either case 1 or 2
This strategy is sometimes known as "Hibbard deletion"
Sets vs. Maps, Summary
Sets vs. Maps
Can think of the BST as representing a Set
But what if we wanted to represent a mapping of word counts?
To represent maps, just have each BST node store key/value pairs
Note: No efficient way to look up by value
Example: Cannot find all the keys with value = 1 without iterating over ALL nodes. This is fine.
Summary
Abstract data types are defined in terms of operations, not implementation
Several useful ADTs: Disjoint Sets, Map, Set, List
Java provides Map, Set, List interfaces, along with several implementations
We've seen two ways to implement a Set (or Map): ArraySet and using a BST
ArraySet: Theta(N) operations in the worst case
BST: Theta(log N) operations if tree is balanced
BST implementations:
Search and insert are straightforward (but insert is a little tricky)
Deletion is more challenging. Typical approach is "Hibbard deletion"
BST Implementation Tips
Tips for BST Lab
Code from class was "naked recursion". Your BSTMap will not be
For each public method, e.g. put(K key, V value), create a private recursive method, e.g. put(K key, V value, Node n)
When inserting, always set left/right pointers, even if nothing is actually changing
Avoid "arms length base cases". Don't check if left or right is null!
CSM Review
A list is an ordered sequence of items: like an array, but without worrying about the length or size
interface List<E> {
boolean add(E element);
void add(int index, E element);
E get(int index);
int size();
}
Maps (Dictionary)
Notes:
Keys are unique
Values don't have to be unique
Key lookup: O(1)
A map is a collection of key-value mappings, like a dictionary in Python
Like a set, the keys in a map are unique
interface Map<K, V> {
V put(K key, V value);
V get(K key);
boolean containsKey(Object key);
Set<K> keySet();
}
Sets
Notes:
Unordered collection of unique items
Set operations are O(1)
A set is an unordered collection of unique elements
Trees range from best-case "bushy" to worst-case "spindly"
Height varies dramatically among the two
Theta(log N) for bushy vs Theta(N) for spindly
Performance of operations on spindly trees can be just as bad as a linked list!
A worst case (spindly tree) has a height that grows exactly linearly - Theta(N)
A best case (bushy tree) has a tree height that grows exactly logarithmically - Theta(log N)
The Usefulness of Big O
Big O is a useful idea:
Allows us to make simple blanket statements, e.g. can just say "binary search is O(log N)" instead of "binary search is Theta(log N) in the worst case"
Sometimes don't know the exact runtime, so use O to give an upper bound
Example: Runtime for finding shortest route that goes to all world cities is O(2^N). There might be a faster way, but nobody knows one yet
Easier to write proofs for Big O than Big Theta, e.g. finding runtime of mergesort, you can round up the number of items to the next power of 2. A little beyond the scope of the course.
Height, Depth, and Performance
Height and Depth
Height and average depth are important properties of BSTs
The "depth" of a node is how far it is from the root
The root has depth 0
The "height" of a tree is the depth of its deepest leaf
The "average depth" of a tree is the average depth of a tree's nodes
Height, Depth, and Runtime
Height and average depth determine runtimes for BST operations
The "height" of a tree determines the worst case runtime to find a node
The "average depth" determines the average case runtime to find a node
Important Question: What about real world BSTs?
BSTs have:
Worst case Theta(N) height
Best case Theta(log N) height
One way to approximate real world BSTs is to consider randomized BSTs
Nice Property. Random trees have Theta(log N) average depth and height
In other words: Random trees are bushy, not spindly
Randomized Trees: Mathematical Analysis
Average Depth. If N distinct keys are inserted into a BST, the expected average depth is ~ 2 ln N
Thus, average runtime for contains operation is Theta(log N) on a tree built with random inserts
Tree Height. If N distinct keys are inserted in random order, expected tree height is ~ 4.311 ln N
Thus, worst case runtime for contains operation is Theta(log N) on a tree built with random inserts
BSTs have:
Worst case Theta(N) height
Best case Theta(log N) height
Theta(log N) height if constructed via random inserts
In real world applications we expect both insertion and deletion
Can show that random trees including deletion are still Theta(log N) height
Good News and Bad News
Good news: BSTs have great performance if we insert items randomly
Performance is Theta(log N) per operation
Bad news: We can't always insert our items in a random order
Data comes in over time, don't have all at once
B-trees / 2-3 trees / 2-3-4 trees
Avoiding Imbalance through Overstuffing
The problem is adding new leaves at the bottom
Crazy idea: never add new leaves at the bottom
Tree can never get imbalanced
Avoid new leaves by "overstuffing" the leaf nodes
"Overstuffed tree" always has balanced height, because leaf depths never change
Overstuffed trees are a logically consistent but very weird data structure
contains(18):
18 > 13? Yes, go right
18 > 15? Yes, go right
16 = 18? No
17 = 18? No
18 = 18? Yes! Found it
Problem with this idea? Degenerates into linked list
Revising Our Overstuffed Tree Approach: Moving Items Up
Height is balanced, but we have a new problem
Leaf nodes can get too juicy
Solution?
Set a limit L on the number of items, say L=3
If any node has more than L items, give an item to parent
Which one? Let's say (arbitrarily) the left-middle
What's the problem now?
16 is to the right of 17
Revising Overstuffed Tree Approach: Node Splitting
Solution?
Set a limit L on the number of items, say L=3
If any node has more than L items, give an item to parent
Pulling item out of full node splits it into left and right
Parent node now has three children!
This is a logically consistent and not so weird data structure
Contains(18):
18 > 13, so go right
18 > 15, so compare vs. 17
18 > 17, so go right
Examining a node costs us O(L) compares, but that's OK since L is constant
What if a non=leaf node gets too full? Can we split that?
add: Chain Reaction
Suppose we add 25, 26:
What Happens if the root is too full?
Perfect Balance
Observation: Splitting-trees have perfect balance
If we split the root, every node gets pushed down by exactly one level
If we split a leaf or internal node, the height doesn't change
All operations have guaranteed O(log N) time
THe Real Name for Splitting Trees is "B Trees"
B-trees of order L=3 (like we used today) are also called a 2-3-4 tree or a 2-4 tree
"2-3-4" refers to the number of children that a node can have
B-trees of order L=2 are also called a 2-3 tree
B-Trees are most popular in two specific contexts:
Small L(L=2 or L=3)
Used as a conceptually simple balanced search tree
L is very large (say thousands)
Used in practice for databases and file systems
B-tree Bushiness Invariants
Exercise
No matter the insertion order you choose, resulting B-Tree is always bushy!
May vary in height a little bit, but overall guaranteed to be bushy
B-Tree Invariants
Because of the way B-Trees are constructed, we get two nice invariants
All leaves must be the same distance from the source
A non-leaf node with k items must have exactly k+1 children
These invariants guarantee that our tree will be bushy
B-Tree Runtime Analysis
Height of a B-Tree with Limit L
L: Max number of items per node
Height: Between ~log_{L+1}(N) and ~log_2(N)
Largest possible height is all non-leaf nodes have 1 item
Smallest possible height is all nodes have L items
Overall height is therefore Theta(log N)
Runtime for contains
Runtime or contains:
Worst case number of nodes to inspect: H + 1
Worst case number of items to inspect per node: L
Overall runtime: O(HL)
Since H = Theta(log N), overall runtime is O(L log N)
Since L is a constant, runtime is therefore O(log N)
Bottom line: contains and add are both O(log N)
Summary
Summary
BSTs have best case height Theta(log N) and worst case height Theta(N)
Big O is not the same thing as worst case
B-Trees are a modification of the binary search tree that avoids Theta(N) worst case
Nodes may contain between 1 and L items
contains works almost exactly like a normal BST
add works by adding items to existing leaf nodes
If nodes are too full, they split
Resulting tree has perfect balance. Runtime for operations is O(log N)
Have not discussed deletion
Have not discussed how splitting works if L > 3
B-trees are more complex, but they can efficiently handle ANY insertion order
2-3 trees (and 2-3-4 trees) are a real pain to implement, and suffer from performance problems. Issues include:
Maintaining different node types
Interconversion of nodes between 2-nodes and 3-nodes
Walking up the tree to split nodes
BST Structure and Tree Rotation
BSTs
Suppose we have a BST with the numbers 1, 2, 3. Five possible BSTs
The specific BST you get is based on the insertion order
More generally, for N items, there are Catalan(N) different BSTs
Given any BST, it is possible to move to a different configuration using "rotation"
In general, can move from any configuration to any other in 2n - 6 rotations
Tree Rotation Definition
rotateLeft(G): Let x be the right child of G. Make G the new left child of x
Preserves search tree property. No change to semantics of tree
Can think of as temporarily G and P, then sending G down and left
rotateRight(P): Let x be the left child of P. Make P the new right child of x
Can think of as temporarily merging G and P, then sending P down and right
Rotation for Balance
Rotation:
Can shorten (or lengthen) a tree
Preserves search tree property
Rotation: An Alternate Approach to Balance
Rotation:
Can shorten (or lengthen) a tree
Preserves search tree property
Paying O(n) to occasionally balance a tree is not ideal. In this lecture, we''l see a better way to achieve balance through rotation
Red-Black Trees
Search Trees
There are many types of search trees:
Binary search trees: Can balance using rotation, but we have no algorithms for doing so (yet)
2-3 trees: Balanced by construction, i.e. no rotations required
Let's try something clever, but strange
Our goal: Build a BST that is structurally identical to a 2-3 tree
Since 2-3 trees are balanced, so will our special BSTs.
Representing a 2-3 Tree as a BST
A 2-3 tree with only 2-nodes is trivial
BST is exactly the same!
What do we do about 3-nodes?
Possibility 1: Create dummy "glue" nodes
Result is inelegant. Wasted link. Code will be ugly
Possibility 2: Create "glue" links with the smaller item off to the left
Idea is commonly used in practice
Left-Leaning Red Black Binary Search Tree (LLRB)
A BST with left glue links that represent a 2-3 tree is often called a
"Left Leaning Red Black Binary Search Tree" or LLRB
LLRBs are normal BSTs
There is a 1-1 correspondence between an LLRB and an equivalent 2-3 tree
The red is just a convenient fiction. Red links don't "do" anything special
Red Black Tree Properties
Left-Leaning Red Black Binary Search Tree (LLRB)
Searching an LLRB tree for a key is easy
Treat it exactly like any BST
Left-Leaning Red Black Binary Search Tree (LLRB) Properties
Some handy LLRB properties:
No node has two red links [otherwise it'd be analogous to a 4 node, which are disallowed in 2-3 trees]
Every path from root to a leaf has same number of black links [because 2-3 trees have the same number of links to every leaf]. LLRBs are therefore balanced
Logarithmic height
LLRB Construction
Where do LLRBs come from?
Would not make sense to build a 2-3 tree, then convert it
Instead, it turns out we implement an LLRB insert as follows:
Insert as usual into a BST
Use zero or more rotations to maintain the 1-1 mapping
Maintaining 1-1 Correspondence Through Rotations
The 1-1 Mapping
There exists a 1-1 mapping between:
2-3 Tree
LLRB
Implementation of an LLRB is based on maintaining this 1-1 correspondence
When performing LLRB operations, pretend like you're a 2-3 tree
Preservation of the correspondence will involve tree rotations
Design Task 1: Insertion Color
Always use a red link when adding onto a leaf
Design Task 2: Insertion on the Right
Right links aren't allowed, so rotateLeft
Likewise, left links aren't allowed, so rotateRight
New Rule: Representation of Temporary 4-Nodes
We will represent temporary 4-nodes as BST nodes with two red links
This state is only temporary, so temporary violation of "left leaning" is ok
Design Task 3: Double insertion on the left
When double inserting on the left, rotate the node to the right
Design Task 4: Splitting Temporary 4-nodes
Suppose we have the LLRB includes a temporary 4 node
To fix this, flip the colors of all edges touching the node
Note: This doesn't change the BST structure/shape
That's it!
We've just invented the red-black BST
When inserting: Use a red link
If there is a right leaning "3-node", we have a Left Leaning Violation
Rotate left the appropriate node to fix
If there are two consecutive left links, we have an Incorrect 4 Node VIolation
Rotate right the appropriate node to fix
If there are any nodes with two red children, we have a Temporary 4 Node
Color flip the node to emulate the split operation
Cascading operations
It is possible that a rotation or flip operation will cause an additional violation that needs fixing
LLRB Runtime and Implementation
LLRB Runtime
The runtime analysis for LLRBs is simple if you trust the 2-3 tree runtime
LLRB tree has height O(log N)
Contains is trivially O(log N)
Insert is O(log N)
O(log N) to add the new node
O(log N) rotation and color flip operations per insert
We will not discuss LLRB delete
Not too terrible really, but it's just not interesting enough to cover. See optional textbook if you're curious
LLRB Implementation
Amazingly, turning BST into an LLRB requires only 3 clever lines of code
Does not include helper methods (which do not require cleverness)
Search Tree Summary
Search Tree
In the last 3 lectures, we talked about using search trees to implement sets/maps
Binary search trees are simple, but they are subject to imbalance
2-3 Trees (B Trees) are balanced, but painful to implement and relatively slow
LLRBs insertion is simple to implement (but delete is hard)
Works by maintaining mathematical bijection with a 2-3 trees
Java's TreeMap is a red-black tree (not left leaning)
Maintains correspondence with 2-3-4 tree (is not a 1-1 correspondence)
Allows glue links on either side
More complex implementation, but significantly faster
There are many other types of search trees out there
Other self balancing trees: AVL trees, splay trees, treaps, etc.
There are other efficient ways to implement sets and maps entirely
Other linked structures: Skip lists are linked lists with express lanes
Other ideas entirely: Hashing is the most common alternative. We'll discuss this idea in the next lecture
CSM Review
B-Trees
B is for balanced
Some definitions:
depth of a node is distance to the root (the root node has depth 0)
height of a tree is the depth of the lowest leaf
Purpose of B-trees:
Avoids spindly trees
Keeps the tree with height log(n)
2-3 Trees
Each non-leaf node can have 2 or 3 children
Each node can be stuffed with at most 2 values
Once a node is overstuffed (aka 3 values), push middle value up
2-3-4 Trees
Same idea as 2-3 trees, but now nodes can have 2, 3, or 4 children
A node is overstuffed if it has 4 values
Push up left-middle node
Traversals
Level-Order Traversals: Nodes are visited top-to-bottom, left-to-right
Depth-First Traversals: Visit deep nodes before shallow ones
Our search tree sets require items to be comparable
Need to be able to ask "is X < Y?" Not true of all types
Could we somehow avoid the need for objects to be comparable
Search tree sets have excellent performance, but could maybe be better
Could we somehow do better than Theta(log N)?
Using Data as an Index
One extreme approach: Create an array of booleans indexed by data!
Initially all values are false
When an item is added, set the appropriate index to true
i.e. 1F 2F 3T 4F 5F 6T 7F 8F ... is a set containing 3 and 6
public class DataIndexedIntegerSet {
private boolean[] present;
public DataIndexedIntegerSet() {
present = new boolean[2000000000];
}
public add(int i) {
present[i] = true;
}
public contains(int i) {
return present[i];
}
}
Everything runs in constant time
Downsides of this approach:
Extremely wasteful of memory. To support checking presence of all positive integers
Need some way to generalize beyond integers
DataIndexedEnglishWordSet
Generalizing the DataIndexedIntegerSet Idea
Ideally, we want a data indexed set that can store arbitrary types
The previous idea only supports integers!
Let's talk about storing Strings. We'll go into generics later
Suppose we want to add ("cat")
The key question:
What is the cat'th element of a list?
One idea: Use the first letter of the word as an index
What's wrong with this approach?
Other words start with c
contains("chupacabra"): true ("chupacabra" collides with "cat")
Can't store "=98tu4it92"
Avoiding Collisions
Use all digits by multiplying each by a a power of 27
Thus, the index of "cat" is (3 x 27^2) + (1 x 27^1) + (20 x 27^0) = 2234
Why this specific pattern?
Let's review how numbers are represented in decimal
THe Decimal Number System vs. Our Own System for Strings
In the decimal number system, we have 10 digits
Want numbers larger than 9? Use a sequence of digits
Our system for strings is almost the same, but with letters
Uniqueness
As long as we pick a base >= 26, this algorithm is guaranteed to give each lowercase English word a unique number!
Using base 27, no words will get the number 1598
In other words: Guaranteed that we will never have a collision
public class DataIndexedEnglishWordSet {
private boolean[] present;
public DataIndexedEnglishWordSet() {
present = new boolean[2000000000];
}
public add(String s) {
present[englishToInt(s)] = true;
}
public contains(String s) {
return present[englishToInt(s)];
}
}
DataIndexedStringSet
DataIndexedStringSet
Using only lowercase English characters is too restrictive
To understand what value we need to use for our base, let's discuss briefly the ASCII standard
Maximum possible value for english-only text including punctuation is 126, so let's use 126 as our base in order to ensure unique values for possible strings
ASCII Characters
THe most basic character set used by most computers is ASCII format
Each possible character is assigned a value between 0 and 127
Characters 33-126 are "printable", and are shown below
For example, char c = 'D' is equivalent to char c = 68
Implementing asciiToInt
The corresponding integer conversion function is actually even simpler than englishToInt. Using the raw character value means we avoid the need for a helper method
Going Beyond ASCII
chars in Java also support character sets for other languages like Chinese
This encoding is known as Unicode. Table is too big to list
Example: Computing Unique Representations of Chinese
The largest possible value for chinese characters is 40959, so we'd need to use this as our base if we want to have a unique representation for all possible strings of Chinese characters
Integer Overflow and Hash Codes
Major Problem: Integer Overflow
In Java, the largest possible integer is 2147483647
If you go over this limit, you overflow, starting back over at the smallest integer, which is -2147483647
Consequence of Overflow: Collisions
Because Java has a maximum integer, we won't get the numbers we expect
With base 126, we will run into overflow even for short strings
Example: omens = 28196917171, which is much greater than the maximum integer
Overflow can result in collisions, causing incorrect answers
Hash Codes and the Pigeonhole Principle
The official term for the number we're computing is "hash code"
A has code "projects a value from a set with many (or even an infinite number of) members to a value from a set with a fixed number of (fewer) members"
Here, our target set is the set of Java integers, which is of size 4294967296
Pigeonhole principle tells us that if there are more than 4294967296 possible items, multiple items will share the same hash code
Hence, collisions are inevitable
Two Fundamental Challenges
Two Fundamental Challenges
How do we resolve hashCode collisions
We'll call this collision handling
How do we compute a hash code for arbitrary objects?
We'll call this computing a hashCode
Hash Tables: Handling Collisions
Resolving Ambiguity
Pigeonhole principle tells us that collisions are inevitable due to integer overflow
Suppose N items have the same numerical representation h:
Instead of storing true in position h, store a "bucket" of these N items at position h
How to implement a "bucket"?
Any type of list or set or data structure
The Separate Chaining Data Indexed Array
Each bucket in our array is initially empty. When an item x gets added at index h:
If bucket h is empty, we create a new list containing x and store it at index h
If bucket h is already a list, we add x to this list if it is not already present
We might call this a "separate chaining data indexed array"
Bucket #h is a "separate chain" of all items that have hash code h
Separate Chaining Performance
Observation: Worst case runtime will be proportional to length of longest list
contains: Theta(Q)
insert: Theta(Q)
Q: Length of longest list
Saving Memory Using Separate Chaining
Observation: We don't really need billions of buckets
If we use just 10 buckets, where should our items go?
Observation: Can use modulus of hashcode to reduce bucket count
Put in bucket = hashCode % 10
Downside: Lists will be longer
The Hash Table
What we've just created here is called a hash table
Data is converted by a hash function into an integer representation called a hash code
The hash code is then reduced to a valid index, usually using the modulus operator, e.g. 2348762878 % 10 = 8
Hash Table Performance
Hash Table Runtime
The good news: We use way less memory and can now handle arbitrary data
The bad news: Worst case runtime (for both contains and insert) is now Theta(Q), where Q is the length of the longest list
For the has table with 5 buckets, the order of growth of Q with respect to N is Theta(N)
In the best case, the length of the longest list will be N/5. IN the worst case, it will be N. In both cases, Q(N) is Theta(N)
Improving the Hash Table
Suppose we have:
A fixed number of buckets M
An increasing number of items N
Major problem: Even if items are spread out evenly, lists are of length Q = N/M
How can we improve our design to guarantee that N/M is Theta(1)
Hash Table Runtime
A solution:
An increasing number of buckets M
An increasing number of items N
One example strategy: When N/M is >= 1.5, then double M
We often call this process of increasing M "resizing"
N/M is often called the "load factor". It represents how full the hash table is
Resizing Hash Table Runtime
As long as M = Theta(N), then O(N/M) = O(1)
Assuming items are evenly distributed, lists will be approximately N/M items long, resulting in Theta(N/M) runtimes
Our doubling strategy ensures that N/M = O(1)
Thus, worst case runtime for all operations if Theta(N/M) = Theta(1)
... unless that operation causes a resize
One important thing to consider is the cost of the resize operation
Resizing takes Theta(N) time. Have to redistribute all items
Most add operations will be Theta(1). SOme will be Theta(N) time (to resize)
Similar to our ALists, as long as we resize by a multiplicative factor, the average runtime will still be Theta(1)
Has Table Runtime
Hash table operations are on average constant time if:
We double M to ensure constant average bucket length
Items are evenly distributed
contains: Theta(1) (Assuming all items are even spaced)
add: Theta(1) (On average)
Regarding Even Distribution
Even distribution of items is critical for good hash table performance
We will need to discuss how to ensure even distribution
Hash Tables in Java
The Ubiquity of Hash Tables
Has tables are the most popular implementation for sets and maps
Great performance in practice
Don't require items to be comparable
Implementations often relatively simple
Python dictionaries are just hash tables in disguise
In Java, implemented as java.util.HashMap and java.util.HashSet
How does a HashMap know how to compute each object's hash code?
Good news: It's not "implements Hashable"
Instead, all objects in Java must implement a .hashCode() method
Objects
All classes are hyponyms of Object
int hashCode() (Default implementation simply returns the memory address of the object)
Examples of Real Java HashCodes
We can see that Strings in Java override hasCode, doing something vaguely like what we did earlier
Will see the actual hashCode() function later
"a".hashCode() // 97
"bee".hashCode() // 97410
Using Negative hash codes
Suppose that we have a hash code as -1
Given a hash table of length 4, we should put this object in bucket 3
Unfortunately, -1 % 4 = -1. Will result in index errors!
Use Math.floorMod instead
-1 % 4 // -1
Math.floorMod(-1, 4) // 3
Hash Tables in Java
Java hash tables:
Data is converted by the hashCode method an integer representation called a hash code
The hash code is then reduced to a valid index, using something like the floorMod function
Two Important Warnings When Using HashMaps/HashSets
Warning #1: Never store objects that can change in a HashSet or HashMap!
If an object's variables changes, then its hasCode changes. May result in items getting lost.
Warning #2: Never override equals without also overriding hashCode
Can also lead to items getting lost and generally weird behavior
HasMaps and HashSets use equals to determine if an item exists in a particular bucket
Good HashCodes
What Makes a good hashCode()?
Goal: We want has tables that are evenly distributed
Want a hasCode that spreads things out nicely on real data
Returning string treated as a base B number can be good
Writing a good hashCode() method can be tricky
Hashbrowns and Hash Codes
How do you make hashbrowns?
Chopping a potato into nice predictable segments? No way!
Similarly, adding up the characters is not nearly "random" enough
Can think of multiplying data by powers of some base as ensuring that all the data gets scrambled together into a seemingly random integer
Example hasCode Function
The Java 8 hash code for strings. Two major differences from our hash codes:
Represents strings as a base 31 number
Why such a small base? Real hash codes don't care about uniqueness
Stores (caches) calculated has code so future hashCode calls are faster
@Override
public int hasCode() {
int h = cachedHashValue;
if (h == 0 && this.length() > 0) {
for (int i = 0; i < this.length; i++) {
h = 31 * h + this.charAt(i);
}
cachedHasValue = h;
}
return h;
}
Example: Choosing a Base
Which is better? ASCII's base 126 or Java's base 31
Might seem like 126 is better. Ignoring overflow, this ensures a unique numerical representation for all ASCII strings
... but overflow is a particularly bad problem for base 126!
Any string that ends in the same last 32 characters has the same has code
Why? Because of overflow
Basic issue is that 126^32 = 126^33 = 126^34 = ... = 0
Thus upper characters are all multiplied by zero
See CS61C for more
Typical Base
A typical hash code base is a small prime
Why prime?
Never even: Avoids the overflow issue on previous slide
Lower chance of resulting hasCode having a bad relationship with the number of buckets
Why small?
Lower cost to compute
Hashbrowns and Hash Codes
Using a prime base yields better "randomness" than using something like base 126
Example: Hashing a Collection
Lists are a lot like strings: Collection of items each with its own hashCode:
@Override
public int hashCode() {
int hashCode = 1;
for (Object o : this) {
hashCode = hashCode * 31; // elevate/smear the current hash code
hashCode = hashCode + o.hashCode(); // add new item's hash code
}
return hashCode
}
To save time hashing: Look at only first few items
Higher chance of collisions but things will still work
Example: Hashing a Recursive Data Structure
Computation of the hashCode of a recursive data structure involves recursive computation
For example, binary tree hashCode (assuming sentinel leaves):
@Override
public int hashCode() {
if (this.value == null) {
return 0;
}
return this.value.hashCode() +
31 * this.left.hashCode() +
31 * 31 * this.right.hashCode();
}
Summary
Hash Tables in Java
Hash tables:
Data is converted into a hash code
The hash code is then reduced to a valid index
Data is then stored in a bucket corresponding to that index
Resize when load factor N/M exceeds some constant
If items are spread out nicely, you get Theta(1) average runtime
/** (Min) Priority Queue: Allowing tracking and removal of the
* smallest item in a priority queue */
public interface MinQP<Item> {
// Adds the item to the priority queue
public void add(Item x);
// Returns the smallest item in the priority queue
public Item getSmallest();
// Removes the smallest item from the priority queue
public Item removeSmallest();
// Returns the size of the priority queue
public int size();
}
Useful if you want to keep track of the "smallest", "largest", "best" etc. seen so far
Usage example: Unharmonious Text
Imagine that you're part of the US Happiness Enhancement team
Your job: Monitor text messages of the citizens to make sure they are not having any unharmonious conversations
Prepare a report of M messages that seem most unharmonious
Naive approach: Create a list of all messages sent for the entire day. Sort it using your comparator. Return the M messages that are largest
Naive Implementation: Store and Sort
Potentially uses a huge amount of memory Theta(N), where N is number of texts
Goal: Do this in Theta(M) memory using a MinPQ
MinPQ<String> unharmoniousTexts = new HeapMinPQ<Transaction>(cmptr);
Better Implementation: Track the M Best
Can track top M transactions using only M memory. API for MinPQ also makes code very simple (don't need to do explicit comparisons)
How Would we Implement a MinPQ?
Some possibilities:
Ordered Array
add: Theta(N)
getSmallest: Theta(1)
removeSmallest: Theta(N)
Bushy BST: Maintaining bushiness is annoying. Handling duplicate priorities is awkward
add: Theta(log N)
getSmallest: Theta(log N)
removeSmallest: Theta(log N)
HashTable: No good! Items go into random places
Heaps
Introducing the Heap
BSTs would work, but need to be kept bushy and duplicates are awkward
Binary min-heap: Binary tree that is complete and obeys min-heap property
Min-heap: Every node is less than or equal to both of its children
Complete: Missing items only at the bottom level (if any), all nodes are as far left as possible
What Good are Heaps?
Heaps lend themselves very naturally to implementation of a priority queue
Questions:
How would you support getSmallest()
Return the root
How Do We Add to a Heap?
Challenge: Come up with an algorithm for add(x)
How would we insert 3?
Add to end of heap temporarily
Swim up to the hierarchy to rightful place
Delete min
Swap the last item in the heap into the root
Then sink your way down the hierarchy, yielding to the most "qualified" items
Heap Operations Summary
Given a heap, how do we implement PQ operations?
getSmallest() - return the item in the root node
add(x) - place the new employee in the last position, and promote as high as possible
removeSmallest() - assassinate the president (of the company), promote the rightmost person in the company to president. Then demote repeatedly, always taking the "better"successor
Tree Representations
How do we represent a tree in Java?
Approach 1a, 1b, and 1c: Create mapping from node to children
public class Tree1A<Key> {
Key k;
Tree1A left;
Tree1A middle;
Tree1A right;
}
public class Tree1B<Key> {
Key k;
Tree1B[] children;
...
}
// Sibling tree
public class Tree1C<Key> {
// Nodes at the same level point to each other's siblings
Key k;
Tree1C favoredChild;
Tree1C sibling;
}
Approach 2: Store keys in an array. Store parentIDs in an array
Similar to what we did with disjointSets
public class Tree2<Key> {
Key[] keys;
int[] parents;
...
}
Approach 3: Store keys in an array. Don't store structure anywhere
To interpret array: Simply assume tree is complete
Obviously only works for "complete" trees
public class Tree3<Key> {
Key[] keys;
}
A Deep Look at Approach 3
Write the parent(k) method for approach 3
public void swim(int k) {
if (keys[parent(k)] > keys[k]) {
swap(k, parent(k));
swim(parent(k));
}
}
public int parent(int k) {
if (k == 0) {
return 0;
}
return (k - 1) / 2;
}
Approach 3B (book implementation): Leaving One Empty Spot in the Front
Approach 3b: Store keys in an array. Offset everything by 1 spot
Same as 3, but leave spot 0 empty
Makes computation of children/parents "nicer"
leftChild(k) = k * 2
rightChild(k) = k * 2 + 1
parent(k) = k / 2
Heap Implementation of a Priority Queue
Heap
add: Theta(log N)
getSmallest: Theta(1)
removeSmallest: Theta(log N)
Notes:
Why "priority queue"? Can think of position in tree as its "priority"
Heap is log N time AMORTIZED (some resizes, but no big deal)
BST can have constant getSmallest if you keep a pointer to smallest
Heaps handle duplicate priorities much more naturally than BSTs
Array based heaps take less memory (very roughly about 1/3) the memory of representing a tree with approach 1a)
Some Implementation Questions
How does a PQ know how to determine which item in a PQ is larger?
What could we change so that there is a default comparison?
What constructors are needed to allow for different orderings?
Data Structures Summary
The Search Problem
Given a stream of data, retrieve information of interest
Examples:
Website users post to personal page. Serve content only to friends
Given logs for thousands of weather stations, display weather map for specified date and time
Search Data Structures (The particularly abstract ones)
Abstraction often happens in layers!
PQ -> Heap Ordered Tree -> Tree -> {Approach 1A, 1B, 1C, 2, 3, 3B}
There are many ways to implement an abstract data type
Today we'll talk about a new way to build a set/map
BST and Hash Table Set Runtimes
Runtimes for our balanced search tree and has table implementations were very fast
If we know that our keys all have some common special property, we can sometimes get even better implementations
Suppose we know that our keys are always single ASCII characters
Special Case 1: Character Keyed Map
Suppose we know that our keys are always ASCII characters
Can just use an array!
Simple and fast
public class DataIndexedCharMap<V> {
private V[] items;
public DataIndexedCharMap(int R) {
items = (V[]) new Object[R];
}
public void put(char c, V val) {
items[c] = val;
}
public V get(char c) {
return items[c];
}
}
Constant time for both get and add
Special Case 2: String Keyed Map
Suppose we know that our keys are always strings
Can use a special data structure known as a Trie
Basic idea: Store each letter of the string as a node in a tree
Tries will have great performance on:
get
add
special string operations
Sets of Strings
For String keys, we can use a "Trie". Key ideas:
Every node stores only one letter
Nodes can be shared by multiple keys
Tries: Search Hits and Misses
How does contains work?
contains("sam"): true, blue node (hit)
contains("sa"): false, white node (miss)
contains("a"): true, blue node (hit)
contains("saq"): false, fell off tree (miss)
Two ways to have a search "miss":
If the final node is white
If we fall off the tree, e.g. contains("sax")
Trie Maps
Tries can also be maps, of course
Tries
Trie:
Short for Retrieval Tree
Inventor Edward Fredkin suggested it should be pronounced "tree", but almost everyone pronounces it like "try"
Trie Implementation and Performance
Very Basic Trie Implementation
The first approach might look something like the code below
Each node stores a letter, a map from c to all child nodes, and a color
public class TrieSet {
private static final int R = 128; // ASCII
private Node root; // root of trie
private static class Node {
private char ch; // Actually don't need this variable
private boolean isKey;
private DataIndexedCharMap next;
private Node(char c, boolean b, int R) {
ch = c; isKey = b;
next = new DataIndexedCharMap<Node>(R);
}
}
}
For each node in DataIndexedCharMap, there are 128 links
Trie Performance in Terms of N
Given a Trie with N keys. What is the:
Add runtime?
Theta(1)
Contains runtime?
Theta(1)
Runtimes independent of number of keys!
Or in terms of L, the length of the key:
Add: Theta(L)
Contains: O(L)
May fall off the tree
When our keys are strings, Tries give us slightly better performance on contains and add
One downside of the DictCharKey based Trie is the huge memory cost of storing R links per node (most of which are null)
Wasteful because most links are not used in real world usage
Alternate Child Tracking Strategies
DataIndexedCharMap Trie
Can use ANY kind of map from character to node, e.g.
BST
Hash Table
Fundamental problem, our arrays are "sparse", wasted memory boxes
Alternate Idea #1: The Hash-Table Based Trie
Alternate Idea #2: The BST-Based Trie
The Three Trie Implementations
When we implement a Trie, we have to pick a map to our children
DataIndexedCharMap: Very fast, but memory hungry
Hash Table: Almost as fast, uses less memory
Balanced BST: A little slower than Hash Table, uses similar amount of memory
Performance of the DataIndexedCharMap, BST, and Hash Table
Using a BST or a Hash Map to store links to children will usually use less memory
DataIndexedCharMap: 128 links per node
BST: C links per node, where C is the number of children
Hash Table: C links per node
Note: Cost per link is higher in BST and Hash Table
Using a BST or a Hash Table will take slightly more time
DataIndexedCharMap is Theta(1)
BST is O(log R), where R is size of alphabet
Hash Table is O(R), where R is size of alphabet
Since R is fixed (e.g. 128), can think of all 3 as Theta(1)
Trie Performance in Terms of N
When our keys are strings, Tries give us slightly better performance on contains and add
Using BST or Hash Table will be slightly slower, but more memory efficient
Would have to do computational experiments to see which is best for your application
...but where Tries really shine is their efficiency with special string operations!
Trie String Operations
String Specific Operations
Theoretical asymptotic speed improvement is nice. But the main appeal of tries is their ability to efficiently support string specific operations like prefix matching
Finding all keys that match a given prefix: keysWithPrefix("sa")
Finding the longest prefix of a string: longestPrefixOf("sample")
Collecting Trie Keys
Give an algorithm for collecting all the keys in a Trie
collect():
Create an empty list of results x
For character c in root.next.keys():
Call colHelp("c", x, root.next.get(c))
Return x
Create colHelp
colHelp(String s, List x, Node n)
If n.isKey, then x.add(s)
For character c in n.next.keys():
Call colHelp(s + c, x, n.next.get(c))
Usages of Tries
Give an algorithm for keysWithPrefix
keysWithPrefix(prefix):
Find the node A corresponding to the string
Create an empty list x
For character c in A.next.keys():
Call colHelp(prefix + c, x, A.next.get(c))
Another common operation: LongestPrefixOf
Autocomplete
The Autocomplete Problem
One way to do this is to create a Trie based map from strings to values
Value represents how important Google thinks that string is
Can store billions of strings efficiently since they share nodes
When a user types in a string "hello", we:
Call keysWithPrefix("hello")
Return the 10 strings with the highest value
The approach has one major flaw. If we enter a short string, the number of keys with the appropriate prefix will be too big
A More Efficient Autocomplete
One way to address this issue:
Each node stores its own value, as well as the value of its best substring
Search will consider nodes in the order of "best"
Can stop when top 3 matches are all better than best remaining
Details left as an exercise. Hint: Use a PQ! See Bear Maps gold points for more
Even More Efficient Autocomplete
Can also merge nodes that are redundant where there's no branching!
This version of trie is known as a "radix tree" or "radix trie"
Won't discuss
Trie Summary
Tries
When your key is a string, you can use a Trie:
Theoretically better performance than hash table or search tree
Have to decide on a mapping from letter to node. Three natural choices:
DataIndexedCharMap, i.e. an array of all possible child links
Bushy BST
Hash Table
All three choices are fine, though hash table is probably the most natural
Supports special string operations like longestPrefixOf and keysWithPRefix
keysWithPrefix is the heart of important technology like autocomplete
Optimal implementation of Autocomplete involves use of a priority queue!
Domain Specific Sets and Maps
More generally, we can sometimes take special advantage of our key type to improve our sets and maps
Example: Tries handle String keys. Allow for fast string specific operations
Note: There are many other types of string sets/maps out there
Discussion Summary: Tries
Tries are special trees mostly used for language tasks
Each node in a trie is marked as being a word-end or not, so you can quickly check whether a word exists within your structure
Goal: Find the shortest path between s and every other vertex
Breadth First Search
Initialize a queue with a starting vertex s and mark that vertex
A queue is a list that has two operations: enqueue (aka addLast) and dequeue (aka removeFirst)
Let's call this queue our fringe
Repeat until queue is empty:
Remove vertex v from the front of the queue
For each unmarked neighbor n of v:
Mark n
Set edgeTo[n] = v (and distTo[n] = distTo[v] + 1)
BreadthFirstSearch for Google Maps
Would breadth first search be a good algorithm for a navigation tool (e.g. Google Maps)?
Assume vertices are intersection and edges are roads connecting intersections
Some roads are longer than others
BAD!
Graph API
Graph Representations
To implement our graph algorithms like BreadthFirstPaths and DepthFirstPaths, we need:
An API (Application Programming Interface) for graphs
Graph methods, including their signatures nad behaviors
Defines how Graph client programmers must think
An underlying data structure to represent our graph
Our choices have profound implications on:
Runtime
Memory usage
Difficulty of implementing algorithms
Graph API Decision #1: Integer Vertices
Common convention: Number nodes irrespective of "label", and use number throughout the graph implementation. To lookup a vertex by label, you'd need to use a Map<Label, Integer>
Graph API
The Graph API from the textbook:
public class Graph {
public Graph(int V); // Create empty graph with v vertices
public void addEdge(int v, int w); // add an edge v-w
Iterable<Integer> adj(int v); // vertices adjacent to v
int V(); // number of vertices
int E(); // number of edges
}
Some features:
Number of vertices must be specified in advance
Does not support weights (labels) on nodes or edges
Has no method for getting the number of edges for a vertex (i.e. its degree)
Example client:
/** degree of vertex v in graph G */
public static int degree(Graph G, int v) {
int degree = 0;
for (int w : G.adj(v)) {
degree += 1;
}
return degree;
}
/** Prints out all the edges in a graph */
public static void print(Graph G) {
for (int v = 0; v < G.V(); v += 1) {
for (int w : G.adj(v)) {
System.out.println(v + "-" + w);
}
}
}
Graph API and DepthFirstPaths
Our choice of Graph API has deep implications on the implementations of DepthFirstPaths, BreadthFirstPath, print, and other graph "clients"
Graph Representation and Graph Algorithm Runtimes
Graph Representations
To implement our graph algorithms like BreadthFirstPaths and DepthFirst Paths, we needed an underlying data structure to represent our graphs
Our choices have implications on:
Runtime
Memory usage
There are many possible implementations we could choose for our graphs
Graph Representation 1: Adjacency Matrix
Represent each edge as a 2-D matrix
For undirected graph:
Each edge is represented twice in the matrix
G.adj(2) would return an iterator where we can call next() and get its adjacent vertices
Total runtime to iterate over all neighbors of v is Theta(V)
Underlying code has to iterate through the entire array to handle next() and hasNext() calls (iterates through an entire row/column of our 2-D matrix)
Graph Printing Runtime
What is the runtime of the print client we wrote if the graph uses an adjacency-matrix representation, where V is the umber of vertices, and E is the total number of edges
Theta(V^2)
Runtime to iterate over v's neighbors is Theta(V)
and we consider V vertices
More Graph Representations
Representation 2: Edge Sets: Collection of all edges
Example: HashSet, where each Edge is a pair of ints
{(0, 1), (0, 2), (1, 2)}
Representation 3: Adjacency lists (most popular approach)
Common approach: Maintain array of lists indexed by vertex number
Most popular approach for representing graphs
Graph Printing Runtime
What is the runtime of the print client we wrote if the graph uses an adjacency-list representation, where V is the umber of vertices, and E is the total number of edges
Theta(V + E)
Create V iterators and print E times
Runtime to iterate over v's neighbors?
Omega(1), O(V)
How many vertices do we consider?
V
Best case: Theta(V)
Worst case: Theta(V^2)
How to interpret: No matter what "shape" of increasingly complex graphs we generate, as V and E grow, the runtime will always grow exactly as Theta(V + E)
Example shape 1: Very sparse graph where E grows ver slowly, e.g. every vertex is connected to its square:
E is Theta(sqrt(V)). Runtime is Theta(V + sqrt(V)), which is just Theta(V)
Example shape 2: Very dense graph where E grows very quickly, e.g. a complete graph
E is Theta(V^2). Runtime is Theta(V + V^2), which is just Theta(V^2)
Runtime of some basic operations for each representation:
In practice, adjacency lists are most common
Many graph algorithms rely heavily on adj(s)
Most graphs are sparse (not many edges in each bucket)
Barebones Undirected Graph Implementation
public class Graph {
private final int V;
private List<Integer>[] adj;
public Graph(int V) {
this.V = V;
adj = (List<Integer>[]) new ArrayList[V];
for (int v = 0; v < V; v++) {
adj[v] = new ArrayList<Integer>();
}
}
public void addEdge(int v, int w) {
adj[v].add(w);
adj[w].add(v);
}
public Iterable<Integer> adj(int v) {
return adj[v];
}
}
Graph Traversal Implementations and Runtime
Depth Fist Search Implementation
Common design pattern in graph algorithms: Decouple type from processing algorithm
Create a graph object
Pass the graph to a graph-processing method (or constructor) in a client class
Query the client class for information
public class Paths {
public Paths(Graph G, int s); // Find all paths from G
boolean hasPathTo(int v); // is there a path from s to v?
Iterable<Integer> pathTo(int v); // path from s to v (if any)
}
DepthFirstPaths Demo
Goal: Find a path from so to every other reachable vertex, visiting each vertex at most once. dfs(v) is as follows:
Mark v
For each unmarked adjacent vertex w:
set edgeTo[w] = v
dfs(w)
DepthFirstPaths, Recursive Implementation
public class DepthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
private int s;
public DepthFirstPaths(Graph G, int s) {
...
dfs(G, s);
}
public void dfs(Graph G, int v) {
marked[v] = true;
for (int w : G.adj(v)) {
if (!marked[w]) {
edgeTo[w] = v;
dfs(G, w);
}
}
}
public boolean hasPathTo(int v) {
return marked[v];
}
public Iterable<Integer> pathTo(int v) {
if (!hasPathTo(v)) return null;
List<Integer> path = new ArrayList<>();
for (int x = v; x !=s; x = edgeTo[x]) {
path.add(x);
}
path.add(s);
Collections.reverse(path);
return path;
}
}
Runtime for DepthFirst Paths
Give a big O bound for the runtime for the DepthFirstPaths constructor (assume graph uses adjacency list)
O(V + E)
Each vertex is visited at most once (O(V))
Vertex visits (no more than V calls)
Each edge is considered at most twice (O(E))
edge considerations (no more than 2E calls)
Cost model in analysis above is the sum of:
Number of dfs calls
marked[w] checks
Runtime for DepthFirstPaths
Very hard question: Could we say the runtime is O(E)?
Argument: Can only visit a vertex if there is an edge to it
Number of DFS calls is bounded above by E
So why not just say O(E)?
Can't say O(E)!
Constructor has to create an all false marked array
This marking of all vertices as false takes Theta(V) time
Our cost model earlier (dfs calls + marked checks) does not provide a tight bound
BreadthFirstPaths Implementation
public class BreadthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
...
private void bfs(Graph G, int s) {
Queue<Integer> fringe = new Queue<Integer>();
fringe.enqueue(s);
marked[s] = true;
while (!fringe.isEmpty()) {
int v = fringe.dequeue();
for (int w : G.adj(v)) {
if (!marked[w]) {
fringe.enqueue(w);
marked[w] = true;
edgeTo[w] = v;
}
}
}
}
}
Runtime for shortest paths is also O(V + E)
Based on cost model: O(V) .next() calls and O(E) marked[w] checks
Note, can't say Theta(V+E), example: Graph with no edges touching source
Space is Theta(V)
Need arrays of length V to store information
Layers of Abstraction
Clients and Our Graph API
Our choice of Graph API has deep implications on the implementation of DepthFirstPaths, BreadthFirstPaths, etc.
Our choice of how to implement the Graph API has profound implications on runtime
Runtime for DepthFirstPaths
Give a tight O bound for the runtime for the DepthFirstPaths constructor
O(V^2)
Summary
Summary
BFS: Uses a queue instead of recursion to track what work needs to be done
Graph API: We used the Princeton Algorithms book API today
Graph Implementations: Saw three ways to implement our graph API
Adjacency matrix
List of edges
Adjacency list (most common in practice)
Choice of implementation has big impact on runtime and memory usage!
DFS and BFS runtime with adjacency list: O(V + E)
DFS and BFS runtime with adjacency matrix: O(V^2)
Discussion Review
Graphs
Graphs are structures that contain nodes and edges
Graphs can be directed or undirected
Graph Representations
Adjacency lists list out all the nodes connected to each node in our graph
In the example below, edges are directed
A: B, C
B: E
C: F
D: B
E:
F: D
Slightly inefficient if graph is more complete
Adjacency matrices are true if there is a line going from node A to B and false otherwise (can be used for directed graphs)
Indexing into a matrix is very fast
However, we have to traverse though all possible children every single time
Graph Searches
Breadth First Search goes in order of how far each node is form the starting node. Programatically this is done using a queue
Depth First Search goes all the way down one path before exploring others. Programatically this is done using a stack
Dijkstra's Algorithm
Dijkstra's algorithm is a method of finding the shortest path from one node to every other node in the graph. You use a priority queue that sorts points based off of their distance to the root node
Steps:
Pop node from the top of the queue - this is the current node
Add/update distance of all of the children of the current node
Re-sort the priority queue
Finalize the distance to the current node from the root
Repeat
A*
A* is a method of finding the shortest path from one node to a specific other node in the graph. It operates similarly to Dijkstra's except for the fact that we use a (given) heuristic to which path is the best to our goal point
Steps:
Pop node from the top of the queue - this is the current node
Add/update distances of all of the children fo the current node. This distance will be the sum of the distance up to that child node and our guess of how far away the goal node is (our heuristic)
Re-sort the priority queue
Check if we've hit the goal node (if so we stop)
Repeat
The only constraints on our heuristic is that it must be less than or equal to the true distance to the goal node
BFS is a 2-for-1 deal, not only do you get paths, but your paths are also guaranteed to be shortest
Time Efficiency. Is one more efficient than the other?
Should be very similar. Both consider all edges twice
Space Efficiency. Is one more efficient than the other?
DFS is worse for spindly graphs
Call stack gets very deep
Computer needs Theta(V) memory to remember recursive calls
BFS is worse for absurdly "bushy" graphs
Queue gets very large. In worst case, queue will require Theta(V) memory
Note: In our implementations, we have to spend Theta(V) memory anyway to track distTo and edgeTo arrays
Breadth FirstSearch for Google Maps
BFS would not be a good choice for a google maps style navigation application
We need an algorithm that takes into account edge distances, also known as "edge weights"
Dijkstra's Algorithm
Single Source Single Target Shortest Paths
Observation: Solution will always be a path with no cycles (assuming non-negative weights)
Problem: Single Source Shortest Paths
Goal: Find the shortest paths from source vertex s to every other vertex
Observation: Solution will always be a tree
Can think of as the union of the shortest paths to all vertices
Edge Count
If G is a connected edge-weighted graph with V vertices and E edges, how many edges are in the Shortest Paths Tree (SPT) of G? [assume every vertex is reachable]
Since the solution is a tree, there are V-1 edges
Creating an Algorithm
Start with a bad algorithm
Algorithm begins with all vertices unmarked and all distance infinite. No edges in the shortest paths tree (SPT)
Bad algorithm #1: Perform a depth first search. When you visit v:
For each edge from v to w, if w is not already part of SPT, add the edge
Note: This WILL NOT WORK
Bad algorithm #2: Perform a depth first search. When you visit v:
For each edge from v to w, add edge to the SPT only if that edge yields better distance (we'll call this process "edge relaxation")
Improvements:
Use better edges if found
Dijkstra's Algorithm
Perform a best first search (closest first). When you visit v:
For each v to w, relax that edge
Improvements:
Use better edges if found
Traverse "best first"
Insert all vertices into fringe PQ (e.g. use a heap), storing vertices in order of distance from source
Repeat: Remove (closest) vertex v from PQ, and relax all edges pointing from v
Note: If non-negative weights, impossible for any inactive vertex (i.e. already visited and not on the fringe) to be improved
Would result in a cycle if it does
Dijkstra's Correctness and Runtime
Dijkstra's Algorithm Pseudocode
Dijkstra's:
PQ.add(source, 0)
For other vertices v, PQ.add(v, infinity)
While PQ is not empty:
p = PQ.removeSmallest()
Relax all edges from p
Relaxing and edge p -> q with weight w:
If distTo[p] + w < distTo[q]:
distTo[q] = distTo[p] + w
edgeTo[q] = p
PQ.changePriority(q, distTo[q])
Key invariants:
edgeTo[v] is the best known predecessor of v
distTo[v] is the best known total distance from source to v
PQ contains all unvisited vertices in order of distTo
Important properties:
Always visits vertices in order of total distance from source
Relaxation always fails on edges to visited (white) vertices
Guaranteed Optimality
Dijkstra's Algorithm
Visit vertices in order of best-known distance from source. On visit, relax every edge from the visited source
Guaranteed to return a correct result if all edges are non-negative
Proof relies on the property that relaxation always fails on edges to visited vertices
Proof sketch: Assume all edges have non-negative weights
At start, distTo[source] = 0, which is optimal
After relaxing all edges from source, let vertex v1 be the vertex with minimum weight, i.e. that is closest to the source. Claim: distTo[v1] is optimal, and thus future relaxations will fail. Why?
distTo[p] >= distTo[v1] for all p, therefore
distTo[p] + w >= distTo[v1]
Can use induction to prove that this holds for all vertices after dequeuing
Negative Edges
Dijkstra's Algorithm
Visit vertices in order of best-known distance from source. On visit, relax every edge from the visited vertex
Dijkstra's can fail if graph has negative weight edges
Relaxation of already visited edges can succeed
Dijkstra's Algorithm Runtime
Priority Queue operation count, assuming binary heap based PQ:
Given an undirected graph, spanning tree T is a subgraph of G, where T:
Is connected
Is acyclic
Includes all of the vertices
A minimum spanning tree is a spanning tree of minium total weight
Ex: Directly connecting buildings by power lines
MST Applications
Handwriting recognition
Medical imaging (e.g. arrangement of nuclei in cancer cells)
MST vs. SPT
A shortest paths tree depends on the start vertex:
Because it tells you how to get from a source to EVERYTHING
There is no source for a minimum spanning tree
Nonetheless, the MST sometimes happens to be a SPT for a specific vertex
However, this is not always true; sometimes, there is no SPT that is the MST
A Useful Tool for Finding the MST: Cut Property
A cut is an assignment of a graph's nodes to two non-empty sets
A crossing edge is an edge which connects a node from one set to a node from the other set
Cut property: Given any cut, minimum weight crossing edge is in the MST
For rest of today, we'll assume edge weights are unique
Cut Property Proof
Suppose that the minimum crossing edge e were not in the MST
Adding e to the MST creates a cycle
Some other edge f must also be a crossing edge
Removing f and adding e is a lower weight spanning tree
Contradiction! e must be in the MST
Generic MST Finding Algorithm
Start with no edges in the MST
Find a cut that has no crossing edges in the MST
Add smallest crossing edge to the MST
Repeat until V-1 edges
This should work, but we need some way of finding a cut with no crossing edges!
Random isn't a very good idea
Prim's Algorithm
Prim's Algorithm
Start from some arbitrary start node
Repeatedly add shortest edge that has one node inside the MST under construction
Repeat until V-1 edges
Why does Prim's work? Special case of generic algorithm
Suppose we add edge e = v->w
Side 1 of cut is all vertices connected to start, side 2 is all the others
No crossing edge is black (all connected edges on side 1)
No crossing edge as lower weight (consider in increasing order)
Prim's Algorithm Implementation
The natural implementation of the conceptual version of Prim's algorithm is highly inefficient
Can use some cleverness and a PQ to speed things up
Prim's Demo
Insert all vertices into fringe PQ, storing vertices in order of distance from tree
Repeat: Remove (closest) vertex v from PQ, and relax all edges pointing from v
Note: Vertex removal in this implementation of Prim's is equivalent to edge addition in the conceptual version of Prim's
No need to reconsider edges that lead to "marked" vertices
Prim's vs. Dijkstra's
Prim's and Dijkstra's algorithms are exactly the same, except Dijkstra's considers "distance from the source", and Prim's considers "distance from the tree."
Visit order:
Dijkstra's algorithm visits vertices in order of distance from the source
Prim's algorithm visits vertices in some order of distance from the MST under construction
Relaxation:
Relaxation in Dijkstra's considers and edge better based on distance to source
Relaxation in Prim's considers an edge better based on distance to tree
Prim's Implementation (Psuedocode)
public class PrimMST {
public PrimMST(EdgeWeightedGraph G) {
edgeTo = new Edge[G.V()];
distTo = new double[G.V()];
marked = new boolean[G.V()];
fringe = new SpecialPQ<Double>(G.V());
distTo[s] = 0.0;
setDistancesToInfinityExceptS(s);
/* Fringe is ordered by distTo tree.
Must be a specialPQ like Dijkstra's */
insertAllVertices(fringe);
/* Get vertices in order of distance from tree */
while (!fringe.isEmpty()) {
// Get vertex closest to tree that is unvisited
int v = fringe.delMin();
// Scan means to consider all of a vertex's outgoing edges
scan(G, v)
}
}
private void scan(EdgeWeightedGraph G, int v) {
marked[v] = true; // Vertex is closest, so add to MST
for (Edge e : G.adj(v)) {
int w = e.other(v);
/* Already in MST, so go to next edge */
if (marked[w]) {continue;}
/* Better path to a particular vertex found,
so update current best known for that vertex */
if (e.weight() < distTo[w]) {
distTo[w] = e.weight();
edgeTo[w] = e;
pq.decreasePriority(w, distTo[w]);
}
}
}
}
Prim's Runtime
What is the runtime of Prim's algorithm?
Assume all PQ operations take O(log V) time
Give your answer in Big O notation
Priority Queue operation count, assume binary heap based PQ:
Insertion: V, each costing O(log V) time
Delete-min: V, each costing O(lov V) time
Decrease priority: O(E), each costing O(log V) time
Overall runtime: O(Vlog(V) + Vlog(V) + E*log(V))
Kruskal's Algorithm
Kruskal's Demo
Consider edges in order of increasing weight. Add to MST unless a cycle is created
Repeat until V-1 edges have been added to the MST
(Really just the cut property in disguise)
Will require a fringe will all edges ordered in smallest weight
Add edges to our MST set and connect the necessary vertices in a WeightedQuickUnion object
Kruskal's Algorithm
Initially mark all edges gray
Consider edges in increasing order of weight
Add edge to MST (mark black) unless doing so creates a cycle
Repeat until V-1 edges
Why does Kruskal's work? Special case of generic MST algorithm
Suppose we add edge e = v->w
Side 1 of cut is all vertices connected to v, side 2 is everything else
No crossing edge is black (since we don't allow cycles)
No crossing edge has lower weight (consider in increasing order)
Kruskal's Implementation (Psueocode)
public class KruskalMST {
private List<edge> mst = new ArrayList<Edge>();
public KruskalMST(EdgeWeightedGraph G) {
MinPQ<Edge> pq = new MinPQ<Edge>();
for (Edge e : G.edges()) {
pq.insert(e);
}
WeightedQuickUnionPC uf =
new WeightedQuickUnionPC(G.V());
while(!pq.isEmpty() && mst.size() < G.V() - 1) {
Edge e = pq.delMin();
int v = e.from();
int w = e.to();
if (!uf.connected(v, w)) {
uf.union(v, w);
mst.add(e);
}
}
}
}
What is the runtime of Kruskal's algorithm?
Assume all PQ operations take O(log(V)) time
Assume all WQU operations take O(log* V) time
Give answer in bit O notation
Kruskal's Runtime
Kruskal's algorithm is O(E log E)
Insertion: E, each costing O(log E) time: O(E log E)
Note: If we use a pre-sorted list of edges (instead of a PQ), then we can simply iterate through the list in O(E) time, so overall runtime is O(E log* V)
Shortest Paths and MSt algorithms Summary
Can we do better than O(E log* V)?
170 Spoiler: State of the Art Compare-Based MST Algorithms
CSM Summary: Graph Algorithms
Depth First Search (DFS)
fringe: Stack
Main idea: Traverse as far as possible from start node, visiting unvisited vertices
Breadth First Search (BFS)
fringe: Queue
Main idea: Traverse vertices based on number of edges from start vertex
Shortest Paths Tree vs Minimum Spanning Tree
Shortest Paths Tree (SPT) from A
Minimizes distance between A and all other vertices
Must define a start vertex
Minimum Spanning Tree (MST)
Minimizes total edge weight (cost) of tree
Shortest Paths Tree Algorithms
Dijkstra's
Priority of each node in PQ is distance to start vertex
Runtime: O((E +V)logV) ~ O(E log V)
A*
Same as Dijkstra's but a heuristic value is added to each node
heuristic: prediction of cost from node to goal
admissible: heuristic is an underestimate of true cost
consistent: difference between heuristics of two nodes is at most the true cost between them
h(A) - h(B) <= cost(A, B)
Runtime: Same as Dijkstra's
Dijkstra's/A*/Prim's Runtime
Runtime: O((E + V)logV) ~ O(E log V)
Usually more edges in a graph than vertices
Runtime analysis:
Add to PQ: O(log V) V times -> O(V log V)
Remove from PQ: O(log V) V times -> O(V log V)
Change priority: O(log V) at most E times -> O(E log V)
E times, since this is the highest possible degree of a vertex
There are E ways to visit this vertex, worst case we update the priority each time
Cut Property
A cut of a graph is a set of edges that separates the vertices of the graph in two
Cut Property: The lightest edge across a cut is in some MST
Reasoning:
MST must span all vertices, so the two parts of the graph must be connected somehow
Minimize total cost of tree by choosing lightest edge as connection
MST Algorithms
Prim's
Similar to Dijkstra's, but Prim's considers distance from tree instead of distance from start vertex
Fringe: priority queue
Priority of each node in queue is the edge weight between that node and the forming tree
Runtime: O(E log V) same analysis as Dijkstra's
The cut in Prim's is the edges between the vertices in the tree so far and those not in the tree. The algorithm then picks the lightest edge across that cut
Kruskal's
Sort edges from least to greatest
Add edges in order as long as the edge doesn't create a cycle
Runtime: O(E log E) <- Dominated by time for sorting edges
How do we check if adding an edge forms a cycle?
Use a disjoint sets data structure
When connecting vertices u and v:
Ask if u and v are connected
If they are not, then we add the edge and union(u, v)
In some ways, we have misled you about what programing entails:
61A: Fill in the function
61B: Implement the class according to our spec
Always working at a "small scale" introduces habits that will cause you great pain later
The goal of these lectures is to gain a sense of how to deal with the "large scale"
Project 3 will give you a chance to encounter "large scale" issues yourself
Complexity Defined
The Power of Software
Unlike other engineering disciplines, software is effectively unconstrained by the laws of physics
Programming is an act of almost pure creativity!
The greatest limitation we face in building systems is being able to understand what we're building! Very unlike other disciplines, e.g.
Chemical engineers have to worry about temperature
Material scientists have to worry about how brittle a material is
Complexity, the Enemy
Our greatest limitation is simply understanding the system we're trying to build!
As real programs are worked on, they gain more features and complexity
Over time, it becomes more difficult for programmers to understand all the relevant pieces as they make future modifications
Tools like IntelliJ, JUnit tests, the IntelliJ debugger, the visualizer, all make it easier to deal with complexity
But our most important goal is to keep our software simple
Dealing with Complexity
There are two approaches to managing complexity
Making code simpler and more obvious
Eliminating special cases, e.g. sentinel nodes
Encapsulation into modules
In a modular design, creators of one "module" can use other modules without knowing how they work
The Nature of Complxity
What is complexity exactly?
Ousterhout: "Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system
Takes many forms:
Understanding how the code works
The amount of time it takes to make small improvements
Finding what needs to be modified to make an improvement
Difficult to fix one bug without introducing another
"If a software system is hard to understand and modify, then it is complicated. If it is asy to understand and modify, then it is simple"
Cost view of complexity:
In a complex system, takes a lot of effort to make small improvements
In a simple system, bigger improvements require less effort
Complexity
Note: Our usage of the term "complex" is not synonymous with "large and sophisticated"
It is possible for even short programs to be complex
Complexity and Importance
Complexity also depends on how often a piece of a system is modified
A system may have a few pieces that are highly complex, but if nobody ever looks at that code, then the overall impact is minimal
Ousterhout gives a crude mathematical formulation:
C = sum(c_p * t_p) for each part p
c_p is the complexity of part p
t_p is time spent working on part p
Symptoms and Causes of Complexity
Symptoms of Complexity
Ousterhout describes three symptoms of complexity:
Change amplification: A simple change requires modification in many places
Cognitive load: How much you need to know in order to make a change
Note: This is not the same as number of lines of code. Often MORE lines of code actually makes code simpler, because it is more narrative
Unknown unknowns: Worst type of complexity. This occurs when it's not even clear what you need to know in order to make modifications
Common in large code bases
Obvious Systems
In a good design, a system is ideally obvious
In an obvious system, to make a change a developer can:
Quickly understand how existing code works
Come up with a proposed change without doing too much thinking
Have a high confidence that the change should actually work, despite not reading much code
Complexity Comes Slowly
Every software system starts out beautiful, pure, and clean
As they are built upon, they slowly twist into uglier and uglier shapes. This is almost inevitable in real systems
Each complexity introduced is no big deal, but: "complexity comes about because hundreds of thousands of small dependencies and obscurities build up over time
"Eventually, there are so many of these small issues that every possible change is affected by several of them"
This incremental process is part of what makes controlling complexity so hard
Ousterhout recommends a zero tolerance philosophy
Strategic vs. Tactical Programming
Tactical Programming
Much (or all) of the programming that you've done, Ousterhout would describe as "tactical"
"Your main focus is to get something working, such as a new feature or bug fix"
The problem with tactical programming:
You don't spend problem thinking about overall design
As a result, you introduce tons of little complexities
Each individual complexity seems reasonable, but eventually you start to feel the weight
Refactoring would fix the problem, but it would also take time, so you end up introducing even more complexity to deal with the original ones
The end result is misery
Strategic Programming
"The first step towards becoming a good software engineer is to realize that working code isn't enough"
"The most important thing is the long term structure of the system"
Adding complexities to achieve short term time games is unacceptable
Strategic programming requires lots of time investment
Try to plan ahead and realize your system is very likely going to be horrible looking when you're done
Suggestions for Strategic Programming
For each new class/task
Rather than implementing the first idea, try coming up with (and possibly even partially implementing) a few different ideas
When you feel like you have found something that feels clean, then fully implement that idea
In real systems: Try to imagine how things might need to be changed in the future, and make sure your design can handle such changes
Strategic Programming is Very Hard
No matter how careful you try to be, there will be mistakes in your design
Avoid the temptation to patch around these mistakes. Instead, fix the design.
E.g. Don't add a bunch of special test cases. Instead, make sure the system gracefully handles the cases you didn't think about
An ordering relation < for keys a, b, and c has the following properties:
Law of Trichotomy: Exactly one of a < b, a = b, b < a is true
Law of Transitivity: If a < b, and a < c, then a < c
An ordering relation with the properties above is known as a "total order"
A sort is a permutation (re-arrangement) of a sequence of elements that puts the keys into non-decreasing order relative to a given ordering relation
Java Note
Ordering relations are typically given in the form of compareTo or compare methods
import java.util.Comparator;
public class LengthComparator implements Comparator<String> {
public int compare(String x, String b) {
return x.length() - b.length();
}
}
Sorting: An Alternate Viewpoint
An inversion is a pair of elements that are out of order with respect to <.
e,g, 0 1 1 2 3 4 8 6 9 5 7 has 6 inversions out of 55 max
Another way to state the goal of sorting:
Given a sequence of elements with Z inversions
Perform a sequence of operations that reduces inversions to 0
Performance Definitions
Characterizations of the runtime efficiency are sometimes called the time complexity of an algorithm. Example:
Dijkstra's has time complexity O(E log V)
Characterizations of the "extra" memory usage of an algorithm is sometimes called the space complexity of an algorithm
Dijkstra's has space complexity Theta(V) (for queue, distTo, edgeTo)
Note that the graph takes up space Theta(V + E), but we don't count this as part of the space complexity of Dijkstra since the graph itself already exists and is an input to Dijkstra's
Selection Sort and Heapsort
Selection Sort
We've seen this already
Find smallest item
Swap this item to the front and "fix" it
Repeat for unfixed items until all items are fixed
Selection sorting N item:
Find the smallest item in the unsorted portion of the array
Move it to the end of the sorted portion of the array
Selection sort the remaining unsorted items
Sort properties:
Theta(N^2) time if we use an array (or similar data structure)
Seems inefficient: We look through entire remaining array every time to find the minimum
Naive Heapsort: Leveraging a Max-Oriented Heap
Idea: Instead of rescanning entire array looking for minimum, maintain a heap so that getting the minimum is fast!
We'll use a max-oriented heap
Naive heapsorting N items:
Insert all items into a max heap, and discard input array. Create output array
Repeat N times:
Delete largest item from the max heap
Put the largest item at the end of the unused part of the output array
Heapsort runtime and memory:
Runtime is O(N log N)
Getting items into the heap O(N log N) time
Selecting largest item: Theta(1)
Removing largest item: O(log N)
Memory usage is Theta(N) to build the additional copy of all of our data
Worse than selection sort
Can eliminate this extra memory cost with some fancy trickery
In-place Heapsort
Alternate approach, treat input array as a heap
Rather than inserting into a new array of length N + 1, use a process known as "bottom-up heapification" to convert the array into a heap
To bottom-up heapify, just sink nodes in reverse level order
Avoids need for extra copy of all data
Once heapified, algorithm is almost the same as naive heap sort
Heap sorting N items:
Bottom-up heapify input array:
Sink nodes in reverse level order: sink(k)
After sinking, guaranteed that tree rooted at position k is a heap
Repeat N times:
Delete largest item from the max heap, swapping root with last item in the heap
Since tree rooted at position 0 is the root of a heap, then entire array is a heap
In-place Heapsort runtime and memory:
Runtime is O(N log N), same as regular heapsort
Best case runtime of Theta(N)
An array of all duplicates will yield linear runtime
Extra: the bottom-up heapification is Theta(N) in the worst case
Memory complexity is Theta(1)
Reuse the same array
The only extra memory we need is a constant number of instance variables (e.g. size)
Unimportant: If we employ recursion to implement various heap operations, space complexity is Theta(log N) due to need to track recursive calls. The difference between Theta(log N) and Theta(1) space is effectively nothing
Has bad cache performance
Mergesort
Mergesort
Mergesort
Split items into 2 roughly even pieces
Mergesort each half (recursively)
Merge the two sorted halves to form the final result
Time complexity: Theta(N log N) runtime
Space complexity with auxiliary array: Costs theta(N) memory
Also possible to do in-place merge sort, but algorithm is very complicated, and runtime performance suffers by a significant constant factor
Insertion Sort
Insertion Sort
General strategy:
Starting with an empty output sequence
Add each item from input, inserting into output at right point
Naive approach, build entirely new output
For naive approach, if output sequence contains k items, worst cost to insert a single item is k
Might need to move everything over
More efficient method:
Do everything in place using swapping
In-place Insertion Sort
General strategy:
Repeat for i = 0 to N - 1:
Designate item i as the traveling item
Swap item backwards until traveller is in the right place among all previously examined items
Runtime analysis:
Omega(N), O(N^2)
Runtime is at least linear since every item is considered as the "traveler" at least once
Observation: Insertion Sort on Almost Sorted Arrays
For arrays that are almost sorted, insertion sort does very little work
Runtime is equal (proportional) to the number of inversions
Insertion Sort Sweet Spots
On arrays with a small number of inversions, insertion sort is extremely fast
One exchange per inversion (and number of comparisons is similar)
Runtime is Theta(N + K) where K is number of inversions
Define an almost sorted array as one in which number of inversions <= cN for some c. Insertion sort is excellent on these arrays
Less obvious: For small arrays (N < 15 or so), insertion sort is fastest
More of an empirical fact than a theoretical one
Theoretical analysis beyond scope of the course
Rough idea: Divide and conquer algorithms like heapsort/mergesort spend too much time dividing, but insertion sort goes straight to the conquest
Selection sort: Find the smallest item and put it at the front
Heapsort variant: Use MaxPQ to find max element and put at the back
Merge sort: Merge two sorted halves into one sorted whole
Insertion sort: Figure out where to insert the current item
Quicksort:
Much stranger core idea: Partitioning
Context for Quicksort's Invention
1960: Tony Hoare was working on a crude automated translation program for Russian and English
How would you do this?
Binary search for each word
Find each word in log D time
Total time to find N words: N log D
Algorithm: N binary searches of D length dictionary
Total runtime: N log D
ASSUMES log time binary search
Limitation at the time:
Dictionary stored on long piece of tape, sentence is an array in RAM
Binary search of tape is not log time (requires physical movement!)
Better: Sort the sentence and scan dictionary tape once. Dictionary is sorted. Takes N log N + D time
But Tony had to figure out how to sort an array
The Core Idea of Tony's Sort: Partitioning
To partition an array a[] on element x = a[i] is to rearrange a[] so that:
x moves to position j (may be the same as i)
All entries to the left of x are <= x
All entries to the right of x are >= x
Interview Question
Given an array of colors where the 0th element is white, and the remaining elements are red (less) or blue (greater), rearrange the array so that all red squares are to the left of the white square, and all blue squares are to the right. Your algorithm must complete in Θ(N) time (no space restriction).
Relative order of red and blues does NOT need to stay the same
Simplest (but not fastest) Answer: 3 Scan Approach
Algorithm: Create another array. Scan and copy all the red items to the first R spaces. Then scan for and copy the white item. Then scan and copy the blue items to the last B spaces.
Quicksort
Partition Sort, a.k.a. Quicksort
Observations:
The partitioning object is "in its place". Exactly where it'd be if the array were sorted
Can sort two halves separately, e.g. through recursive use of partitioning
Quicksorting N items:
Partition on leftmost item
Quicksort left half
Quicksort right half
Quicksort
Quicksort was the name chosen by Tony Hoare for partition sort
For most common situations, it is empirically the fastest sort
How fast is Quicksort? Need to count number and difficulty of partition operations
Theoretical analysis:
Partitioning costs Theta(K) time, where Theta(K) is the number of elements being partitioned
The interesting twist: Overall runtime will depend crucially on where pivot ends up
Quicksort Runtime
Best Case: Pivot Always Lands in the Middle
What is the best case runtime?
Total work at each "level": N
Number of "levels": H = Theta(log N)
So overall runtime is Theta(HN) = Theta(N log N)
Worst Case: Pivot Always Lands at Beginning of Array
What is the worst case runtime?
Total work at each "level": N
Number of "levels": N
So overall runtime is N^2
Quicksort Performance
Theoretical analysis:
Best case: Theta(N log N)
Worst case: Theta(N^2)
Compare this to Mergesort
Best case: Theta(N log N)
Worst case: Theta(N log N)
Recall that Theta(N log N) vs. Theta(N^2) is a really big deal. So how can Quicksort be the fastest sort empirically? Because on average it is Theta(N log N) (proof requires probability theory and calculus)
(Intuitive) Argument #1 for Average Runtime: 10% Case
Suppose pivot always ends up at least 10% from either edge
Work at each level: O(N)
Runtime is O(NH) (H = number of levels)
H is approximately log_{10/9}N = O(log N)
Overall: O(N log N)
Even if you're unlucky enough to have a pivot that never lands in the middle, but at least always 10% from the edge, runtime is still O(N log N)
(Intuitive) Argument #2: Quicksort is BST Sort
Key idea: compareTo calls are same for BST insert and Quicksort
Every number gets compared to the partitioning number in both
Reminder: Random insertion into a BST takes O(N log N) time
Empirical Quicksort Runtimes
For N items:
Mean number of compares to complete Quicksort: ~2N ln N
Standard deviation is about 0.6482776N
Very few arrays take a ridiculous number of comparisons
Given a random seed (long), generate a 2D world (TetTile[][]) with rooms and hallways
N: Create new world
343434: Random seed
S: End of seed marker
Part 2: Interactivity
In part 2, you'll add:
An interactive keyboard mode
The ability for the avatar to move around in the world
Must also be able to handle movements given via interactWithInputString
Ousterhout's Take on Complexity
There are two primary sources of complexity:
Dependencies: When a piece of code cannot be read, understood, and modified independently
Obscurity: When important information is not obvious
Modular Design
Hiding Complexity
One powerful tool for managing complexity is to design your system so that programmer is only thinking about some of the complexity at once
Using helper methods (i.e. getNeighbor(WEST) and helper classes (InputDevice)) hide complexity
Modular Design
In an ideal world, system would be broken down into modules, where every module would be totally independent
Here, "module" is an informal term referring to a class, package, or other unit of code
Not possible for modules to be entirely independent, because code from each module has to call other modules
e.g. need to known signature of methods to call them
In modular design, out goal is to minimize dependencies between modules
Interface vs. Implementation
As we've seen, there is an important distinction between Interface and Implementation
Map is an interface
HashMap, TreeMap, etc. are implementations
"The best modules are those whose interfaces are much simpler than their implementation"
A simple interface minimizes the complexity the module can cause elsewhere
If you only have a getNext() method, that's all someone can do
If a module's interface is simple, we can change an implementation of that module without affecting the interface
If List had an arraySize method, this would mean you'd be stuck only being able to build array based lists
Interface
A Java interface has both a formal and an informal part:
Formal: The list of method signatures
Informal: Rules for using the interface that are not enforced by the compiler
Example: If your iterator requires hasNext to be called before next in order to work properly, that is an informal part of the interface
Example: If your add method throws an exception on null inputs, that is an informal part of the interface
Example: Runtime for a specific method, e.g. add in ArrayList
Can only be specified in comments
Be wary of the informal rules of your modules as you build project 3
Modules Should be Deep
Ousterhout: "The best modules are those that provide powerful functionality yet have simple interfaces. I use the term deep to describe such modules"
For example, the KdTree is a deep module
Simple interface:
Constructor takes a list of inputs
nearest method that takes a point and returns closest point in set
Nothing informal the user needs to know
Powerful functionality:
List converted into a complex searchable binary tree
Nearest method has complex and subtle pruning rules for efficiency
Information Hiding
The most important way to make your modules deep is to practice "information hiding"
Embed knowledge and design decision in the module itself, without exposing them to the outside world
Reduces complexity in two ways:
Simplifies interface
Makes it easier to modify the system
Information Leakage
The opposite of information hiding is information leakage
Occurs when design decision is reflected in multiple modules
Any change to one requires a change to all
Information is embodied in two places, i.e. it has "leaked"
Ousterhout:
"Information leakage is one of the most important red flags in software design"
Temporal Decomposition
One of the biggest causes of information leakage is "temporal decomposition"
In temporal decomposition, the structure of your system reflects the order in which events occur
BYOW Suggestions
Some suggestions for BYOW:
Build classes that provide functionality needed in many places in your code
Create "deep modules", e.g. classes with simple interfaces that do complicated things
Avoid over-reliance on "temporal decomposition" where your decomposition is driven primarily by the order in which things occur
It's OK to use some temporal decomposition, but try to fix any information leakage that occurs
Be strategic, not tactical
Most importantly: Hide information from yourself when unneeded!
Teamwork
Project 3
Project 3 is a team project
Two main reasons:
Get practice working on a team
Get more creativity into the project since it's so open ended
Teamwork
In the real world, some tasks are much too large to be handled by a single person
When faced with the same task, some teams succeed, where others may fail
Individual Intelligence
In 1904, Spearman very famously demonstrated the existence of an "intelligence" factor in humans:
"People who do well on mental task tend to do well on most others, despite large variations in the tests' contents and methods of administration." This mysterious factor is called "intelligence"
Intelligence can be quickly measured (less than an hour)
Intelligence reliably predicts important life outcomes over a long period of time, including:
Grades in school
Success in occupations
Life expectancy
Note: There is nothing in Spearman's work that says this factor is genetic
Group Intelligence
Wooley et. al investigated the success of teams of humans on various tasks
They found that performance on a wide variety of tasks is correlated, i.e. groups that do well on any specific task tend to do very well on the others
This suggests that groups do have "group intelligence" analogous to individual intelligence
Studying individual group members, Wooley et. al found that:
Collective intelligence is not significantly correlated with average or max intelligence of each group
Instead, collective intelligence was correlated with three things:
Average social sensitivity of group members as measured using the "Reading the Mind in the Eyes Test"
How equally distributed the group was in conversational turn-taking, e.g. groups where one person dominated did poorly
Percentage of females in the group (paper suggests this is due to correlation with greater social sensitivity)
Teamwork and Project 3
Presumably, learning habits that lead to greater group intelligence is possible
Recognize that teamwork is also about relationships!
Treat each other with respect
Be open and honest with each other
Make sure to set clear expectations
...and if those expectations are not met, confront this fact head on
Reflexivity
Important part of teamwork is "reflexivity"
"A group's ability to collectively reflect upon team objectives, strategies, and processes, and to adapt to them accordingly"
Recommended to "cultivate a collaborative environment in which giving and receiving feedback on an ongoing basis is seen as a mechanism for reflection and learning"
Feedback is Hard: Negativity
Most of us have received feedback from someone which felt judgmental or in bad faith
Thus, we're afraid to given even constructive negative feedback for fear that our feedback will be misconstrued as an attack
And we're conditioned to watch out for negative feedback that is ill-intentioned
Feedback is Hard: Can Seem Like a Waste of Time
Feedback also can feel like a waste of time:
You may find it a pointless exercise to rate each other twice during the project. What does that have to do with a programming class?
In the real world, the same thing happens. Your team has limited time to figure out "what" to do, so why stop and waste time reflecting on "how" you're working together?
Feedback is Hard: Coming Up With Feedback is Tough
Feedback can simply difficult to produce
You may build incredible technical skills, but learning to provide useful feedback is hard!
Without confidence in ability to provide feedback, you may wait until you are forced to do so by annual reviews or other structured time to provide it
If you feel like your partnership could be better, try to talk about it without waiting until you have to review each other at the end of next week
Team Reflection
We are going to have you reflect on your team's success twice:
This partnership has worked well for me
This partnership has worked well for my partner
Estimate the balance of work between you and your partner
Contribution in a more general sense
If applicable, give a particularly great moment from your partnership
What's something you could do better?
What's something your partner could do better?
In extreme cases, we will not be penalizing partners who contributed less
Run time is Theta(N log N) in the best case, Theta(N^2) in the worst case, and Theta(N log N) in the average case
Avoiding the Worst Case
Four philosophies:
Randomness: Pick a random pivot or shuffle before sorting
Smarter pivot selection: Calculate or approximate the median
Introspection: Switch to a safer sort if recursion goes too deep
Preprocess the array: Could analyze array to see if Quicksort will be slow. No obvious way to do this, though
Philosophy 1: Randomness (Preferred Approach)
If pivot always lands somewhere "good", Quicksort is Theta(N log N). However, the ver rare Theta(N^2) cases do happen in practice
Bad ordering: Array already in sorted order
Bad elements: Array with all duplicates
Deal with bad ordering:
Strategy 1: Pick pivots randomly
Strategy 2: Shuffle before sorting
THe second strategy requires care in partitioning code to avoid Theta(N^2) behavior on arrays of duplicates
Common bug in textbooks!
Philosophy 2a: Smarter Pivot Selection (constant time pivot pick)
Randomness is necessary for best Quicksort performance! For any pivot selection procedure that is:
Deterministic
Constant time
The resulting Quicksort has a family of dangerous inputs that an adversary could easily generate
Philosophy 2b: Smarter Pivot Selection (linear time pivot pick)
Could calculate the actual median in linear time
"Exact median Quicksort" is safe: Worst case Theta(N log N), but it is slower than Mergesort
Raises interesting question though: How do you compute the median or an array? Will talk about how to do this later today
Philosophy 3: Introspection
Can also simply watch your recursion depth
If it exceeds some critical value (say 10 ln N), switch to mergesort
Sorting Summary (so far)
Listed by mechanism:
Selection sort: Find smallest item and put it at the front
Insertion sort: Figure out where to insert the current item
Merge sort: Merge two sorted halves into one sorted whole
Partition (quick) sort: Partition items around a pivot
Quicksort Flavors
Quicksort is the fastest, but only if we make the right decisions about:
Pivot selection
Partition algorithm
How we deal with avoiding the worst case
Tony Hoare's In-place Partitioning Scheme
Proposed scheme where two pointers walk towards each other
Left pointer loves small items and hates large or equal items
Right pointer loves large items and hates small or equal items
Big idea: Walk pointers toward each other, stopping on a hated item
When both pointers have stopped, swap and move pointers by one towards each other
End result is that things on left are "small" and things on the right are "large"
When pointers cross, you are done
Swap pivot where right pointer ends up
This partitioning scheme yields a very fast Quicksort and is faster than mergesort
Though faster schemes have been found since
Best known Quicksort uses a two-pivot scheme
Overall runtime still depends crucially on pivot selection strategy!
What if we don't want randomness?
Another approach: Use the median (or an approximation)
The best possible pivot is the median
Splits problem into two problems of size N/2
Median Identification
Is it possible to find the median in Theta(N) time?
Yes! Use 'BFPRT' (called PICK in original paper)
In practice, rarely used
However, while runtime is still Theta(N log N) this makes quicksort much slower than mergesort
Quick Select
The Selection Problem
Computing the exact median would be great for picking an item to partition around. Gives us a "safe quick sort"
Unfortunately, it turns out that exact median computation is too slow
However, it turns out that partitioning can be used to find the exact median
The resulting algorithm is the best known median identification algorithm
Quick Select
Goal, find the median
Keep partitioning until the pivot lands in the exact middle of the array
Only need to partition the half that contains the middle index of the array
Worst Case Performance of Quick Select
Worst asymptotic performance Theta(N^2) occurs if array is in sorted order
Can mostly negate this using shuffling
Expected Performance
On average, Quick Select will take Theta(N) time
On average, pivot ends up about halfway:
Number of compares: N + N/2 + N/8 + ... + 1 ~~ Theta(N)
Quicksort with Quickselect
What if we used Quickselect to find the exact median?
Resulting algorithm is still quite slow. Also: a little strange to do a bunch of partitions to identify the optimal item to partition around
Stability, Adaptiveness, Optimization
Other Desirable Sorting Properties: Stability
A sort is said to be stable if order of equivalent items is preserved
Equivalent items don't "cross over" when being stably sorted
Sorting Stability
Is insertion sort stable?
Yes
Equivalent items never move past their equivalent elements
Is Quicksort stable?
Depends on partitioning strategy
Three array partitioning will be stable
Hoare partitioning may not be stable (we may swap equivalent items)
Stability
Optimizing Sorts
Additional tricks we can play:
Switch to insertion sort:
When a subproblem reaches size 15 or lower, use insertion sort
Make sort adaptive: Exploit existing order in array (Insertion Sort, SmoothSort, TimSort)
Exploit restrictions on set of keys. If number of keys is some constant, can sort faster
For Quicksort: Make the algorithm introspective, switching to a different sorting method if recursion goes too deep. Only a problem for deterministic flavors of Quicksort
Arrays.sort
In Java, Arrays.sort(someArray) uses:
Mergesort if someArray consists of objects
Quicksort if someArray consists of primitives
Sorting Summary
Sorting Landscape
The landscape of the sorting algorithms we've studied
Three basic flavors: Comparison, Alphabet, and Radix based
Each can be used in different circumstances, important part was the analysis and the deep thought
Sorting vs Searching
During the data structures part of the class, we studied what we called the "search problem": Retrieve data of interest
There are some interesting connections between the two
We'll discus your role in the future we're creating
Workplace Preference
Income and pay
Passion about a subject
Marquee branding for your career
Security of career
Skill sets
Different cultures
The Ledger of Harms
Concerns Expressed by Tech Leaders
"I think we have created tools that are ripping apart the social fabric of how society works."
"God only knows that it's doing to our children's brains"
"The technologies we were most excited about 10 years ago are now implicated in just about every catastrophe of the day"
"Facebook appeals to your lizard brain -- pimarily fear and anger
Hug's Thoughts
Technology companies do inflict significant negative externalities upon society
Most of them are still a net positive, e.g. I personally use and enjoy facebook
My personal sense is that these are largely unintended consequences by well intentioned people
Yes, there are some bad actors, but I don't think they are common
Workers and executives at these companies do care
...but money does skew people's perspective in strange ways
The Center for Humane Technology and the Ledger of Harms
The Center for Humane Technology was founded by current and former tech workers to raise awareness and try to combat harmful side effects of internet tech platforms
In 2018, they created a Ledger of Harms "collect those negative impacts of social media and mobile tech that do not show up on the balance sheets of companies, but on the balance sheet of society."
"aimed at guiding rank-and-file engineers who are concerned about what they are being asked to build"
The Ledger of Harms
Their concerns:
Attention: Loss of ability to focus without distraction
Mental Health: Loneliness, depression, stress, loss of sleep, increased risk of suicide
Relationships: Less empathy, more confusion and misinterpretation
Democracy: Propaganda, lies, an unreliable and noisy place to talk
Children: New challenges learning and socializing
Your Life
The Power of Software
Unlike other engineering disciplines, software is effectively unconstrained by the laws of physics
Programming is an act of almost pure creativity!
The creates limitation we face in building systems is being able to understand what we're building!
The Limiting Reagent
You are a rare commodity
The skills you are building will be in high demand from companies, non-profits, government agencies, educational institutions, and more
The choice of how to spend your career is yours
Steering the Course
Quite a lot of you will likely end up working at some sort of tech company at some point in your life
There's nothing (IMO) wrong with working at profit driven tech companies
Please do realize that even as a rank and file employee, you have the power to effect change, particularly if you are paid in stock (because then you are a partial owner)
TIme
You get some number of decades on the planet
Each week is 168 hours
40 hours of work
56 hours of sleep
72 hours for everything else
Spend your time wisely, in both your career and personal life
We have shown several sorts to require Theta(N log N) worst case time
Can we build a better sorting algorithm?
Let the ultimate comparison sort (TUCS) be the asymptotically fastest possible comparison sorting algorithm, possibly yet to be discovered, and let R(N) be its worst case runtime in Theta notation
Comparison sort means that it uses the compareTo method in Java to make decisions
Worst case rn-time of TUCS, R(N), is O(N log N)
We already have algorithms that take Theta(N log N) worst case
Worst case run-time of TUCS, R(N) is Omega(1)
Obvious: Problem doesn't get easier than N
Can we make a stronger statement than Omega(1)?
Worst case run-time of TUCS, R(N), is also Omega(N)
Have to at least look at every item
But, with a clever argument, we can see that the lower bound will turn out to be Omega(N log N)
This lower bound means that across the infinite space of all possible ideas that any human might ever have for sorting using sequential comparisons, NONE has a worst case runtime that is better than N log N
The Game of Puppy, Cat, Dog
Suppose we have a puppy, a cat, and a dog, each in an opaque soundproof box labeled A, B, and C. We want to figure out which is which using a scale
We have to weigh a and c to resolve the final ambiguity
Puppy, Cat, Dog - A Graphical Picture of N = 3
The full decision tree for puppy, cat, dog:
The Game of Puppy, Cat, Dog
How many questions would you need to ask to definitely solve the "puppy, cat, dog, walrus" question?
If N = 4, we have 4! = 24 permutations of puppy, cat, dog, walrus
So we need a binary tree with 24 leaves
How many levels minimum? log_2(24) = 4.5, so 5 is the minimum
So at least 5 questions
Generalized Puppy, Cat, Dog
How many questions would you need to ask to definitely solve the generalized "puppy, cat, dog" problem for N items?
Give your answer in big Omega notation
Answer: Omega(log(N!))
For N, we have the following argument:
Decision tree needs N! leaves
So we need log_2(N!) rounded up levels, which is Omega(log(N!))
Generalizing Puppy, Cat, Dog
Finding an optimal decision tree for the generalized version of puppy, cat, dog is an open problem in mathematics
Deriving a sequence of yes/no questions to identify puppy, cat, dog is hard. An alternate approach to solving the puppy, cat, dog algorithm
Sort the boxes using any generic sorting algorithm
Leftmost box is puppy
Middle box is cat
Right box is dog
Sorting, Puppies, Cats, and Dogs
A solution to the sorting problem also provides a solution to puppy, cat, dog
In other words, puppy, cat, dog reduces to sorting
Thus, any lower bound on difficulty of puppy, cat, dog must ALSO apply to sorting
Sorting Lower Bound
We have a lower bound on puppy, cat, dog, namely it takes Omega(log(N!)) comparisons to solve such a puzzle
Since sorting with comparisons can be used to solve puppy, cat, dog, then sorting also takes Omega(log(N!)) comparisons
Or in other words:
Any sorting algorithm using comparisons, no matter how clever, must use at least k = log_2(N!) compares to find the correct permutation. So even TUCS takes at least log_2(N!) comparisons
log_2(N!) is trivially Omega(log(N!)), so TUCS must take Omega(log(N!)) time
Earlier, we showed the log(N!) \in Theta(N log N), so we have that TUCS is Omega(N log N)
Any comparison based sort requires at least order N log N comparisons
Proof summary:
Puppy, cat, dog is Omega(log_2(N!)), i.e. requires log_2(N!) comparisons
TUCS can solve puppy, cat, dog, and thus takes Omega(log_2(N!)) compares
log_2(N!) is Omega(N log N)
This was because N! is Omega((N/2)^(N/2))
Optimality
The punchline:
Our best sorts have achieved absolute asymptotic optimality
Mathematically impossible to sort using fewer comparisons
Note: Randomized quicksort is only probabilistically optimal, but the probability is extremely high for even modest N. So don't worry about quicksort
The key idea from our previous sorting lecture: Sorting requires Omega(N log N) compares in the worst case
Thus, the ultimate comparison based sorting algorithm has a worst case runtime of Theta(N log N)
What about sorts that don't use comparisons
Example 1: Sleep Sort (for sorting integers) (not actually good)
For each integer x in array A, start a new program that:
Sleeps for x seconds
Prints x
All start at the same time
Runtime:
N + max(A)
The catch: On real machines, scheduling execution of programs must be done by operating system. In practice requires list of running programs sorted by sleep time
Example 2: Counting Sort: Exploiting Space Instead of Time
Assuming keys are unique integers 0 to 11
Idea:
Create a new array
Copy item with key i into ith entry of new array
Generalizing Counting Sort
We just sorted N items in Theta(N) worst case time
Avoiding yes/no questions lets us dodge our lower bound based on puppy, cat, dog
Simplest case:
Keys are unique integers from 0 to N-1
More complex cases:
Non-unique keys
Non-consecutive keys
Non-numerical keys
Implementing Counting Sort with Counting Arrays
Counting sort:
Count number of occurrences of each item
Iterate through list, using count array to decide where to put everything
Bottom line, we can use counting sort to sort N objects in Theta(N) time
Counting Sort Runtime
Counting Sort vs. Quicksort
For sorting an array of the 100 largest cities by population, which sort do you think has a better expected worst case runtime in seconds?
Quicksort is better
Counting sort requires building an array of size 37832892 (population of Tokyo)
Counting Sort Runtime Analysis
What is the runtime for counting sort on N keys with alphabet of size R?
Treat R as a variable, not a constant
Total runtime on N keys with alphabet of size R: Theta(N + R)
Create an array of size R to store counts: Theta(R)
Counting number of each item: Theta(N)
Calculating target positions of each item: Theta(R)
Creating an array of size N to store ordered data: Theta(N)
Copying items from original array to ordered array: Do N items:
Check target position: Theta(1)
Update target position: Theta(1)
Copying items from ordered array back to original array: Theta(N)
Memory usage: Theta(N + R)
N is for ordered array
R is for counts and starting points
Bottom line: If N is >= R, then we expect reasonable performance
Empirical experiments needed to compare vs. Quicksort on practical inputs
Counting Sort vs. Quicksort
For sorting really really big collections of items from some alphabet, which algorithm will be fastest?
Lecture 36: Radix vs. Comparison Sorting, Sorting and Data Structures Conclusion
11/20/2020
Intuitive: Radix Sort vs. Comparison Sorting
Merge Sort Runtime
Merge Sort requires Theta(N log N) compares
What is Merge Sort's runtime on strings of length W?
It depends!
Theta(N log N) if each comparison takes constant time
Example: Strings are all different in top character
Theta(WN log N) if each comparison takes Theta(W) time
Example: Strings are all equal
LSD vs. Merge Sort
The facts
Treating alphabet size as constant, LSD Sort has runtime Theta(WN)
Merge Sort has runtime between Theta(N log N) and Theta(WN log N)
Which is better? It depends
When might LSD sort be faster
Sufficiently large N
If strings are very similar to each other
Each Merge Sort comparison costs Theta(W) time
When might Merge Sort be faster?
If strings are highly dissimilar from each other
Each Merge Sort comparison is very fast
Cost Model: Radix Sort vs. Comparison Sorting
Alternate Approach: Picking a Cost Model
An alternate approach is to pick a cost model
We'll use number of characters examined
By "examined", we mean:
Radix Sort: Calling charAt in order to count occurrences of each character
Merge Sort: Calling charAt in order to compare two Strings
MSD vs. Mergesort
Suppose we have 100 strings of 1000 characters each
Estimate the total number of characters examined by MSD Radix Sort if all strings are equal
For MSD Radix Sort, in the worst case (all strings equal), every character is examined exactly once. Thus we have exactly 100,000 total character examinations
Estimate the total number of characters examined by Merge Sort if all strings are equal
Merging 100 items, assuming equal items results in always picking left
Total characters examined in a single merge operation: 50 * 2000 = 100,000 (= N/2 * 2000 = 1000N)
In total, we must examine approximately 1000Nlog_2(N) total characters
100000 + 50000*2 + 25000*4 + ... = ~660,000
MSD vs. Mergesort Character Examinations
For N equal strings of length 1000, we found that:
MSD radix sort will examine ~1000N characters
Mergesort will examine ~1000Nlog_2(N) characters
If character examination are an appropriate cost model, we'd expect Merge Sort to be slower by a factor of log_2(N)
Empirical Study: Radix Sort vs. Comparison Sorting
Computational Experiment Results
Computational experiment for W = 100
As we expected, Merge sort considers log_2(N) times as many characters
But empirically, Mergesort is MUCH faster than MSD sort
Our cost model isn't representative of everything that is happening
One particularly thorny issue: The "Just In Time" (JIT) Compiler
An Unexpected Factor: The Just-In-Time Compiler
Java's Just-In-Time COmpiler secretly optimizes your code when it runs
The code you write is not necessarily the code that executes!
As your code runs, the "interpreter" is watching everything that happens
If some segment of code is called many times, the interpreter actually studies and re-implements your code based on what it learned by watching WHILE ITS RUNNING (!!)
Example: Performing calculations whose results are unused
Rerunning Our Empirical Study Without JIT
Computational Experiments Results with JIT disabled
Results with JIT disabled (using the -Xint option)
Both sorts are MUCH slower than before
Merge sort is slower than MSD (though not by as much we predicted)
What this tells us: The JIT was somehow able to massively optimize the compareTo calls
Makes some intuitive sense: Comparing "AAA...A" to "AAA...A" over and over is redundant
So Which is Better? MSD or MergeSort?
We showed that if the JIT is enabled, merge sort is much faster for the case of equal strings, and slower if JIT is disabled
Since JIT is usually on, I'd say merge sort is better for this case
Many other possible cases to consider:
Almost equal strings (maybe the trick used by the JIT won't work?)
Randomized strings
Real world data from some dataset of interest
In real world applications, you'd profile different implementations of real data and pick one
Bottom Line: Algorithms Can be Hard to Compare
Comparing algorithms that have the same order of growth is challenging
Have to perform computational experiments
Experiments can be tricky due to optimizations like the JIT in Java
Note: There's always the chance that some small optimization to an algorithm can make it significantly faster
Radix Sorting Integers (61C Preview)
Linear Time Sorting
As we've seen, estimating radix sort vs. comparison sort performance is very hard
But in the very large N limit, it's easy. Radix sort is simply faster!
Treating alphabet size as constant, LSD Sort has runtime Theta(WN)
Comparison sorts have runtime Theta(N log N) in the worst case
Issue: We don't have a charAt method for integers
How would you LSD radix sort an array of integers
Convert into a String and treat as a base 10 number. Since the maximum Java int is 2,000,000,000, W is also 10
Could modify LSD radix sort to work natively on integers
Instead of using charAt, maybe write a helper method like getDthDigit(int D, int d). Example: getDthDigit(15009, 2) = 5
LSD Radix Sort on Integers
Note: There's no reason to stick with base 10!
Could instead treat as a base 16, base 256, base 65536 number
Ex: 512,312 in base 16 is a 5 digit number
Ex: 512,312 in base 256 is a 3 digit number
Relationship Between Base and Max # Digits
For Java integers:
R=10, treat as a base 10 number. Up to 10 digits
R=256, treat as a base 256 number. Up to 4 digits
$ = 65335, treat as a base 65536 number. Up to 2 digits
Interesting fact: Runtime depends on the alphabet size
As we saw with the city sorting last time, R = 2147483647 will result in a very slow radix sort (since it's just counting sort)
Another Counting Sort
Results of a computational experiment:
Treating as a base 256 (4 digits), LSD radix sorting integers easily defeats Quicksort
Sorting Summary
Sorting Landscape
Three basic flavors: Comparison, Alphabet, and Radix based
Comparison based algorithms:
Selection -> If heapify first -> Heapsort
Merge
Partition
Insertion -> If insert into BST, equiv. to Partition
Small-Alphabet (e.g. Integer) algorithms:
Counting
Radix Sorting algorithms (require a sorting subroutine)
LSD and MSD use Counting as a subroutine
Each can be used in different circumstances, but the important part was the analysis and the deep thought!
Sorting vs. Searching
We've now concluded our study of the "sort problem"
During the data structures part of the class, we studied what we called the "search problem": Retrieve data of interest
There are some interesting connections between the two
Search-By-Key-Identity Data Structures
Sets and Maps:
2-3 Tree (Uses compareTo(), Analogous to Comparison-Based)
RedBlack Tree (Uses compareTo(), Analogous to Comparison-Based)
Separate Chaining (Searches using hashCode() and equals(), Roughly Analogous to Integer Sorting)
Tries (searches digit-by-digit Roughly Analogous to Radix Sorting)
Count relative frequencies of all characters in a text
Split into "left" and "right" halves of roughly equal frequency
Left half gets a leading zero. Right half gets a leading one
Repeat
Shannon-Fano coding is NOT optime. Does a good job, but possible to find "better" codes
Huffman Coding
Code Calculation Approach #2: Huffman Coding
Calculate relative frequencies
Assign each symbol to a node with weight = relative frequency
Take the two smallest nodes and merge them into a super node with weight equal to sum of weights
Repeat until everything is part of a tree
Huffman Coding Data Structures
Prefix-Free Codes
Question: For encoding (bitstream to compressed bitstream), what is a natural data structure to use? Assume characters are of type Character, and bit sequences are of type bitSequence. Two approaches:
Array of BitSequence[], to retrieve, can use character as index
Faster than HashMap
Question: For decoding (compressed bitstream back to bitstream), what is a natural data structure to use?
We need to look up longest matching prefix, an operation that Tries excel at
Huffman Coding in Practice
Huffman Compression
Two possible philosophies for using Huffman Compression:
For each input type, assemble huge numbers of sample inputs for that category. Use each corpus to create a standard code for English, Chinese, etc
For every possible input file, create a unique code just for that file. Send the code along with the compressed file
What are some advantages/disadvantages of each idea? Which is better?
Approach 1 will result in suboptimal encoding
Approach 2 requires you to use extra space for the codeword table in the compressed bitstream
For very large inputs, the cost of including the codeword table will become insignificant
In practice, Philosophy 2 is used in the real world
Huffman Compression Steps
Given input text:
Count frequencies
Build encoding array and decoding trie
Write decoding trie to output
Write codeword for each symbol to output
Huffman Decompression Steps
Given input bitstream:
Read in decoding trie
Use codeword bits to walk down the trie, outputting symbols every time you reach a leaf
Huffman Coding Summary
Given a file X.txt that we'd like to compress into X.huf:
Consider each b-bit symbol of X.txt, counting occurrences of each of the 2^b possibilities, where b is the size of each symbol in bits
Use Huffman code construction algorithm to create a decoding trie and encoding map. Store this trie at the beginning of X.huf
Use encoding map to write codeword for each symbol of input into X.huf
To decompress X.huf:
Read in the decoding trie
Repeatedly use the decoding trie's longestPrefixOf operation until all bits in X.hug have been converted back to their uncompressed form
Compression Theory
Compression Algorithms (General)
The big idea in Huffman Coding is representing common symbols with small numbers of bits
Many other approaches:
Run-length encoding: Replace each character by itself concatenated with the number of occurrences
LZW: Search for common repeated patterns in the input
General idea: Exploit redundancy and existing order inside the sequence
Sequences with no existing redundancy or order may actually get enlarged
Comparing Compression Algorithms
Different compression algorithms achieve different compression ratios on different files
Universal Compression: An Impossible Idea
There is no universal compression algorithm
Intuitive idea: There are far fewer short bitstreams than long ones
A Sneaky Situation
Universal compression is impossible, but comparing compression algorithms could still be quite difficult
Compression Model #2: Self-Extracting Bits
As a model for the decompression process, let's treat the algorithm and the compressed bitstream as a single sequence of bits
Can think of the algorithm + compressed bitstream as an input to an interpreter. Interpreter somehow executes those bits
At the very "bottom" of these abstractions is some kind of physical machine